链研社
用戶暫無簡介
链研社
Claude 開始反蒸餾和封號的究極手段了,KYC...
中國人天塌了
查看原文中國人天塌了

- 打賞
- 按讚
- 留言
- 轉發
- 分享
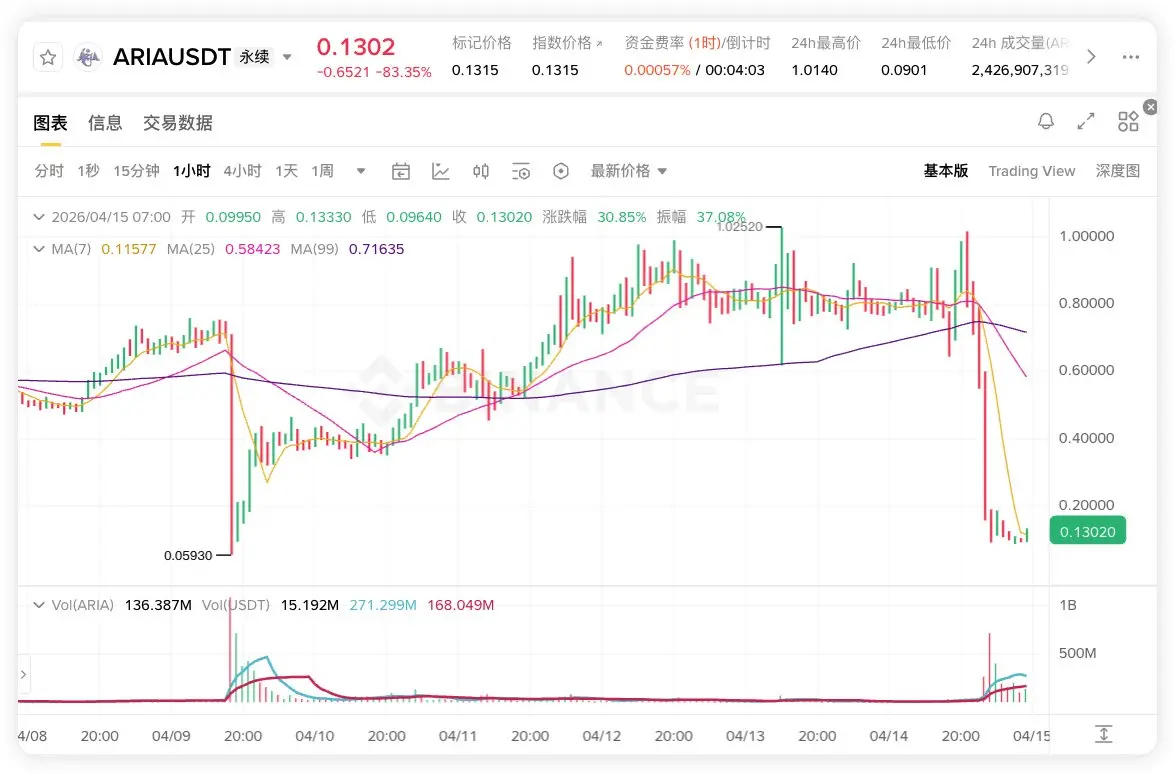
試用了一下Qwen Code 還挺好用的,每天有 1000 次額度,每分鐘最多 60 次,沒有 Token 上限,基本是夠用了,命令行的功能都有中文註釋。
Qwen Code 是用 Gemini Code 開源代碼的二次開發,現在上面用的是最新的模型 Qwen3.6 plus,coding 模型能力排全球第九弱於 GLM5.1(全球第三),現在的Qwen3.6 plus還只是中等模型的,Qwen3.6 max 的旗艦模型能力應該會超過GLM5.1,正常是在plus一個月左右發布,估計 5 月就能看到,4 月底還有 DeepSeek 的新模型,Qwen 旗艦模型登頂國內第一還是有點難度的
Github 開源倉庫:QwenLM/qwen-code
查看原文Qwen Code 是用 Gemini Code 開源代碼的二次開發,現在上面用的是最新的模型 Qwen3.6 plus,coding 模型能力排全球第九弱於 GLM5.1(全球第三),現在的Qwen3.6 plus還只是中等模型的,Qwen3.6 max 的旗艦模型能力應該會超過GLM5.1,正常是在plus一個月左右發布,估計 5 月就能看到,4 月底還有 DeepSeek 的新模型,Qwen 旗艦模型登頂國內第一還是有點難度的
Github 開源倉庫:QwenLM/qwen-code
- 打賞
- 按讚
- 留言
- 轉發
- 分享
試用了一下Qwen Code 還挺好用的,每天有 2000 次額度,每分鐘最多 60 次,沒有 Token 上限,基本是夠用了,命令行的功能都有中文註釋。
Qwen Code 是用 Gemini Code 開源代碼的二次開發,現在上面用的是最新的模型 Qwen3.6 plus,coding 模型能力排全球第九弱於 GLM5.1(全球第三),現在的Qwen3.6 plus還只是中等模型的,Qwen3.6 max 的旗艦模型能力應該會超過GLM5.1,正常是在plus一個月左右發布,估計 5 月就能看到,4 月底還有 DeepSeek 的新模型,Qwen 旗艦模型登頂國內第一還是有點難度的
Github 開源倉庫:QwenLM/qwen-code
查看原文Qwen Code 是用 Gemini Code 開源代碼的二次開發,現在上面用的是最新的模型 Qwen3.6 plus,coding 模型能力排全球第九弱於 GLM5.1(全球第三),現在的Qwen3.6 plus還只是中等模型的,Qwen3.6 max 的旗艦模型能力應該會超過GLM5.1,正常是在plus一個月左右發布,估計 5 月就能看到,4 月底還有 DeepSeek 的新模型,Qwen 旗艦模型登頂國內第一還是有點難度的
Github 開源倉庫:QwenLM/qwen-code
- 打賞
- 按讚
- 留言
- 轉發
- 分享
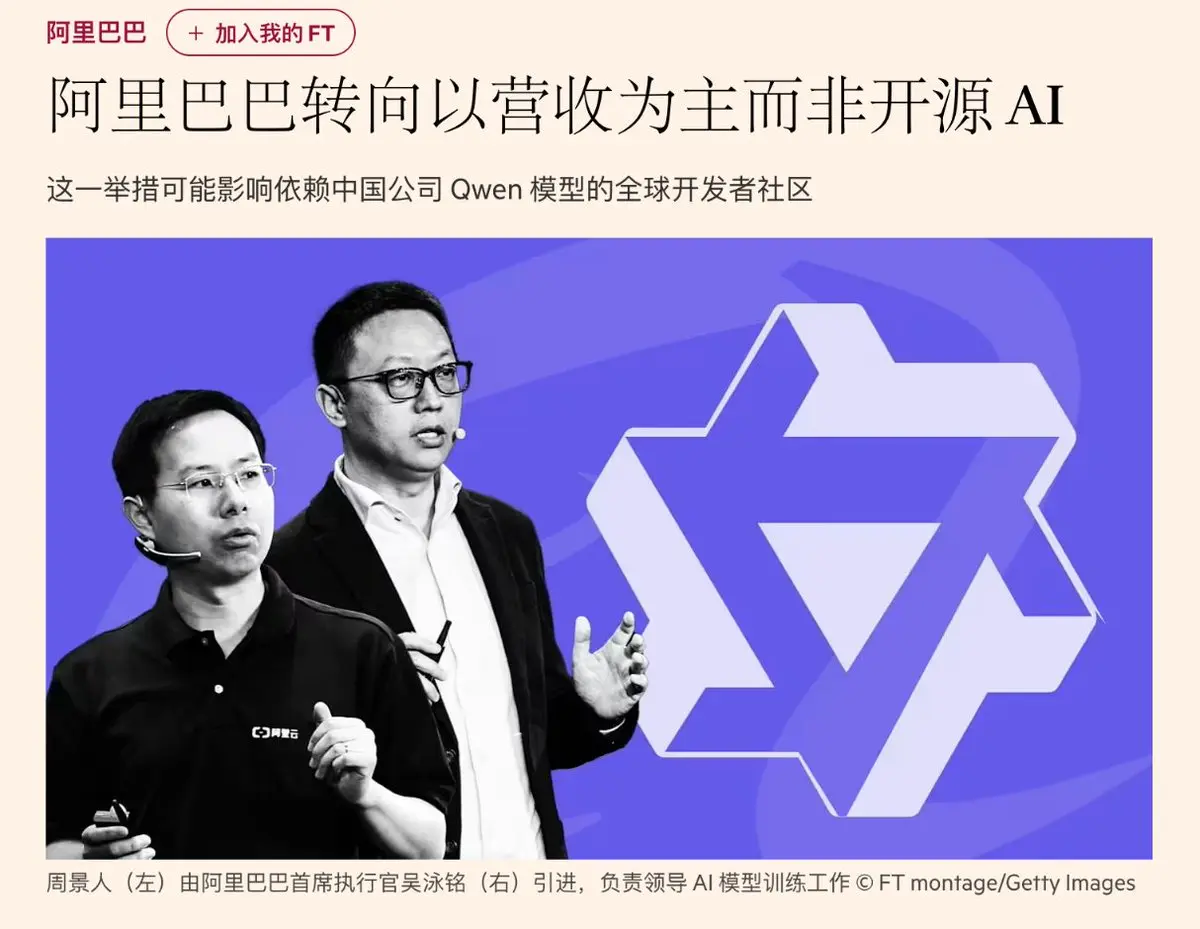
阿里巴巴对 AI 发展进行战略转向,从追求开源生态转向商业变现,Qwen 团队核心人物林俊阳、胡斌元等因战略分歧离职,阿里云前 CTO 周靖人接手,CEO 吴泳铭成立"Alibaba Token Hub"并组建 AI 策略委员会,明确将模型开发与云业务营收目标对齐,公司明确转向,MaaS 和商业化优先。
转型逻辑在当下是非常正确的选择,Qwen 开源虽然获得了全球开发者的口碑,但模型本身并不赚钱。阿里云 AI 收入的大头仍是卖 GPU 算力,MaaS 占比很小且利润薄,有第一梯队的模型能力和大量的 GPU 算力赚的却是微薄的利润,这在商业上是不可持续且失败的。
改革以后,阿里在 AI 上的战略变得和字节在 AI 上的战略高度一致,豆包从一开始就是闭源的,火山引擎一开始就是围绕以 AI 变现为逻辑建设的,Token 的调用量全球第一,把 Token 货币化上走的最前,尽管模型能力不是第一但,但变现率并不比 qwen 差。
转型的代价是,Qwen 开源生态的灵魂人物林俊阳出走,他的离开可能动摇社区信心并引发人才链式流失。更关键的是,MiniMax、智谱等竞争对手在代码生成上已超越 Qwen,模型能力本身在承压。此时转闭源,若产品力不够强,客户只会转向竞品。同时字节跳动的火山引擎增长凶猛,在 token 消费驱动的云销售模式上已抢先布局,毛利比阿里云的卖 GPU 算力高了不知道多少。
所
转型逻辑在当下是非常正确的选择,Qwen 开源虽然获得了全球开发者的口碑,但模型本身并不赚钱。阿里云 AI 收入的大头仍是卖 GPU 算力,MaaS 占比很小且利润薄,有第一梯队的模型能力和大量的 GPU 算力赚的却是微薄的利润,这在商业上是不可持续且失败的。
改革以后,阿里在 AI 上的战略变得和字节在 AI 上的战略高度一致,豆包从一开始就是闭源的,火山引擎一开始就是围绕以 AI 变现为逻辑建设的,Token 的调用量全球第一,把 Token 货币化上走的最前,尽管模型能力不是第一但,但变现率并不比 qwen 差。
转型的代价是,Qwen 开源生态的灵魂人物林俊阳出走,他的离开可能动摇社区信心并引发人才链式流失。更关键的是,MiniMax、智谱等竞争对手在代码生成上已超越 Qwen,模型能力本身在承压。此时转闭源,若产品力不够强,客户只会转向竞品。同时字节跳动的火山引擎增长凶猛,在 token 消费驱动的云销售模式上已抢先布局,毛利比阿里云的卖 GPU 算力高了不知道多少。
所
- 打賞
- 按讚
- 留言
- 轉發
- 分享
比Seedance2.0牛逼的HappyHorse 竟然還開源?
HappyHorse 背後的人是淘天集團的張迪,之前是快手Kling一號位,再之前是阿里媽媽大數據與機器學習工程架構負責人,在阿里待了 10 年,去年被老東家重新請回去。
不過阿里的公關宣傳你懂的,實際用起來可能還要打個折扣,對標Seedance2.0,打平Kling還是可能的,關鍵是開源啊,那還要啥自行車
查看原文HappyHorse 背後的人是淘天集團的張迪,之前是快手Kling一號位,再之前是阿里媽媽大數據與機器學習工程架構負責人,在阿里待了 10 年,去年被老東家重新請回去。
不過阿里的公關宣傳你懂的,實際用起來可能還要打個折扣,對標Seedance2.0,打平Kling還是可能的,關鍵是開源啊,那還要啥自行車
- 打賞
- 2
- 留言
- 轉發
- 分享
中國大模型的作弊蒸餾之路要被海外御三家聯手封殺了,國內大模型的好日子到頭了,看看誰會先原形畢露😂
kimi、minimax、DeepSeek 都是上了蒸餾黑名單的,GLM 和 Qwen 倒是沒被點名
查看原文kimi、minimax、DeepSeek 都是上了蒸餾黑名單的,GLM 和 Qwen 倒是沒被點名
- 打賞
- 按讚
- 留言
- 轉發
- 分享
Qwen3.6-Plus 我實測下來是明顯強於MiniMax M2.7還是多模態,但是這次沒有那麼多 AI 博主出彩虹屁評測了,因為阿里把他們斷糧了。
大概是阿里因為最近一次財報的問題,把宣傳的預算給砍了,要我說這樣才對啊,本來就應該憑實力征服,Qwen3.5 出來的時候,搞那麼多預算鋪墊蓋地吹的天花亂墜,結果實測就是一坨屎。
阿里現在的策略轉向
- 小模型、小尺寸 Qwen3.5 全開源第一時間開源
- 中等模型 Qwen3.6-Plus 性能超過 MiniMax M2.7 應該會延遲開源,效仿另外三家國產模型
- 旗艦模型 Qwen max 系列,閉源
Qwen3.5-Plus 到 Qwen3.5-Max 大概間隔 1 個月時間,等Qwen3.6-Plus出來之後有可能重登國產模型第一,但是這期間 DeepSeek V4 也要出來了,還有其他國產模型大概也要更新了,目前落後進度 1~2 個月,在各家轉向閉源之後Qwen追上是不難,因為國產模型最大的 BUG (蒸餾)已經被 Claude 封堵,蒸餾在開始的時候追進度很快,智能提升非常明顯,之後就看各家的硬實力如何了。
查看原文大概是阿里因為最近一次財報的問題,把宣傳的預算給砍了,要我說這樣才對啊,本來就應該憑實力征服,Qwen3.5 出來的時候,搞那麼多預算鋪墊蓋地吹的天花亂墜,結果實測就是一坨屎。
阿里現在的策略轉向
- 小模型、小尺寸 Qwen3.5 全開源第一時間開源
- 中等模型 Qwen3.6-Plus 性能超過 MiniMax M2.7 應該會延遲開源,效仿另外三家國產模型
- 旗艦模型 Qwen max 系列,閉源
Qwen3.5-Plus 到 Qwen3.5-Max 大概間隔 1 個月時間,等Qwen3.6-Plus出來之後有可能重登國產模型第一,但是這期間 DeepSeek V4 也要出來了,還有其他國產模型大概也要更新了,目前落後進度 1~2 個月,在各家轉向閉源之後Qwen追上是不難,因為國產模型最大的 BUG (蒸餾)已經被 Claude 封堵,蒸餾在開始的時候追進度很快,智能提升非常明顯,之後就看各家的硬實力如何了。
- 打賞
- 按讚
- 留言
- 轉發
- 分享
中國的大模型紛紛轉向半開源了,最新發布的大模型全都沒有立即開源,承諾開源的到現在也還沒有開,
說明行業已經走過了用開源換注意力的階段,進入用閉源換利潤的商業化階段
GLM 5.1 沒有第一時間開
MiniMax 2.7 沒有開
Qwen 3.6 Plus 也沒有開
現在基本轉向延遲開源甚至閉源,立即開源等於直接把自己的護城河拆掉。
查看原文說明行業已經走過了用開源換注意力的階段,進入用閉源換利潤的商業化階段
GLM 5.1 沒有第一時間開
MiniMax 2.7 沒有開
Qwen 3.6 Plus 也沒有開
現在基本轉向延遲開源甚至閉源,立即開源等於直接把自己的護城河拆掉。
- 打賞
- 2
- 留言
- 轉發
- 分享
做了一個 Deribit 的期權工具,方便做賣出期權抄底,就別玩交易所的雙幣理財了,自己手搓不好嗎?用Deribit 的開放 API 做的,找到適合的賣出期權,篩選出 APR 合適、流動性好。用數據大概判斷現在的波動率歷史情況是高還是低,什麼時候賣權划算,聰明錢方向等
github 倉庫 :lianyanshe-ai/deribit-options-monitor
監控了Deribit交易所BTC/ETH期權市場,設計 skill 的思路
1. DVOL波動率分析
- 計算DVOL波動率指數Z-Score值,判斷波動率高低區間
- 隨行情閾值動態調整,附帶信號置信度評估,方便判斷
- 歷史波動率趨勢回溯
2. Sell Put 標的智能推薦
- 掃描全市場期權合約,按到期年化收益率(APR)排序,推薦合適的
- 自動排除流動性差、風險收益比不合理的標的,降低操作風險
3. 大宗交易異動監控
- 監控大額Call/Put訂單流向,巨鯨資金布局動向
- 分析市場多空情緒變化
- 可以設定監控預警,異常波動自動觸發告警
查看原文github 倉庫 :lianyanshe-ai/deribit-options-monitor
監控了Deribit交易所BTC/ETH期權市場,設計 skill 的思路
1. DVOL波動率分析
- 計算DVOL波動率指數Z-Score值,判斷波動率高低區間
- 隨行情閾值動態調整,附帶信號置信度評估,方便判斷
- 歷史波動率趨勢回溯
2. Sell Put 標的智能推薦
- 掃描全市場期權合約,按到期年化收益率(APR)排序,推薦合適的
- 自動排除流動性差、風險收益比不合理的標的,降低操作風險
3. 大宗交易異動監控
- 監控大額Call/Put訂單流向,巨鯨資金布局動向
- 分析市場多空情緒變化
- 可以設定監控預警,異常波動自動觸發告警
- 打賞
- 按讚
- 留言
- 轉發
- 分享
投資裡最難賺的錢,不是消息的錢,也不是情緒的錢,是預期差的錢。
所謂預期差,就是你對一家公司的理解,比市場更早、更準。市場還沒看見的變化,被你提前看到了;市場還沒接受的邏輯,被你提前接受了。等市場慢慢反應過來,股價就開始兌現你的認知。
預期差主要有三種。
第一種是業績預期差
市場原來只預期公司賺10個億,你通過調研判斷它能賺15個億。那多出來的5個億,就是你的優勢。但它也最難。你要懂需求、價格、成本、產能、競爭格局,稍有偏差,就會從超預期變成幻想。
第二種是估值預期差
不是簡單地覺得公司便宜,是提前看到大多數人還沒接受的定價邏輯。比如,一家公司原本被當成普通消費品,但你認為它其實更接近奢侈品,應該給更高估值比如泡泡瑪特。一旦市場接受這種邏輯,股價就會重估。問題是,這種預期差很容易講故事,也很容易被證伪,兌現不了,也是虛妄。
第三種是產業趨勢預期差
除了看一家公司,更重要的是看一個行業。你比市場更早判斷出某個產業趨勢增長,趨勢一旦成立,最先漲的往往不是最完美的公司,是最先被看懂的公司。這類投資看起來像投趨勢,實質上還是認知差。
但預期差有一個致命弱點:它怕時間。
你對了,市場卻遲遲不認;或者你看對了方向,卻拿不到兌現的那一刻,邏輯就可能失效。預期差的錢,賺的是你比市場更早。
真正成熟的投資者,往往都經歷過一段追逐預期差的歲月。
他們試過尋找市場沒看到的東西,試過提前押注變化,試過享受
查看原文所謂預期差,就是你對一家公司的理解,比市場更早、更準。市場還沒看見的變化,被你提前看到了;市場還沒接受的邏輯,被你提前接受了。等市場慢慢反應過來,股價就開始兌現你的認知。
預期差主要有三種。
第一種是業績預期差
市場原來只預期公司賺10個億,你通過調研判斷它能賺15個億。那多出來的5個億,就是你的優勢。但它也最難。你要懂需求、價格、成本、產能、競爭格局,稍有偏差,就會從超預期變成幻想。
第二種是估值預期差
不是簡單地覺得公司便宜,是提前看到大多數人還沒接受的定價邏輯。比如,一家公司原本被當成普通消費品,但你認為它其實更接近奢侈品,應該給更高估值比如泡泡瑪特。一旦市場接受這種邏輯,股價就會重估。問題是,這種預期差很容易講故事,也很容易被證伪,兌現不了,也是虛妄。
第三種是產業趨勢預期差
除了看一家公司,更重要的是看一個行業。你比市場更早判斷出某個產業趨勢增長,趨勢一旦成立,最先漲的往往不是最完美的公司,是最先被看懂的公司。這類投資看起來像投趨勢,實質上還是認知差。
但預期差有一個致命弱點:它怕時間。
你對了,市場卻遲遲不認;或者你看對了方向,卻拿不到兌現的那一刻,邏輯就可能失效。預期差的錢,賺的是你比市場更早。
真正成熟的投資者,往往都經歷過一段追逐預期差的歲月。
他們試過尋找市場沒看到的東西,試過提前押注變化,試過享受
- 打賞
- 2
- 留言
- 轉發
- 分享
OpenAI 說要做一個整合 ChatGPT、編程平台 Codex 以及 成一個統一的桌面端超級應用
然後發現豆包的桌面端更是大亂炖、聊天、瀏覽器、生圖、視頻,這些都有了而且早半年以前就是這樣了😂
查看原文然後發現豆包的桌面端更是大亂炖、聊天、瀏覽器、生圖、視頻,這些都有了而且早半年以前就是這樣了😂
- 打賞
- 按讚
- 留言
- 轉發
- 分享
特朗普亂搞之後美聯儲先松口了。
美聯儲主席鮑威爾:通脹預期似乎已穩定下來。
交易員們取消了對美聯儲加息的預期,並將今年降息的可能性納入考量。
查看原文美聯儲主席鮑威爾:通脹預期似乎已穩定下來。
交易員們取消了對美聯儲加息的預期,並將今年降息的可能性納入考量。
- 打賞
- 按讚
- 留言
- 轉發
- 分享
小米萬億參數大模型 MiMo-v2pro 繼續免費體驗一周,教你如何快速上手體驗,支持在OpenClaw 免費使用。
現在免費真的很值得試一下,體驗下來感覺是國產第一梯隊不為過。官方定義為面向 agentic workflow 的旗艦模型:總參數規模超過 1T,支持 1M 上下文,重點強化了複雜流程編排、工程任務推進和真實開發工作流里的可用性。
可以在 OpenClaw、OpenCode、KiloCode、Blackbox 和 Cline 裡免費體驗,推薦用OpenClaw、OpenCode來體驗。
一、openclaw 里免費使用
1、註冊 openrouter,拿到 API Key
2、openclaw config,model,openrouter
3、搜索 mimo,空格選中openrouter/xiaomi/mimo-v2-pro
4、在對話框輸入/model 切換到 mimo-v2-pro 即可
後續如果到期openrouter也可以切換到其他免費模型,推薦stepfun/step-3.5-flash:free,後面有其他廠商在openrouter上免費試用也可以通過同樣的方式來操作。
二、OpenCode 里免費使用
儘管小米推薦了很多編程 Agent,但是我覺得最適合的還是 OpenCode,因為支持了終端版、桌面版 Beta,還有各大編程工具的入口。
對新手來說
查看原文現在免費真的很值得試一下,體驗下來感覺是國產第一梯隊不為過。官方定義為面向 agentic workflow 的旗艦模型:總參數規模超過 1T,支持 1M 上下文,重點強化了複雜流程編排、工程任務推進和真實開發工作流里的可用性。
可以在 OpenClaw、OpenCode、KiloCode、Blackbox 和 Cline 裡免費體驗,推薦用OpenClaw、OpenCode來體驗。
一、openclaw 里免費使用
1、註冊 openrouter,拿到 API Key
2、openclaw config,model,openrouter
3、搜索 mimo,空格選中openrouter/xiaomi/mimo-v2-pro
4、在對話框輸入/model 切換到 mimo-v2-pro 即可
後續如果到期openrouter也可以切換到其他免費模型,推薦stepfun/step-3.5-flash:free,後面有其他廠商在openrouter上免費試用也可以通過同樣的方式來操作。
二、OpenCode 里免費使用
儘管小米推薦了很多編程 Agent,但是我覺得最適合的還是 OpenCode,因為支持了終端版、桌面版 Beta,還有各大編程工具的入口。
對新手來說
- 打賞
- 按讚
- 留言
- 轉發
- 分享
轉自孤独大脑
語言是人类最伟大的發明,也是人类最大的瓶颈。
當大模型拆掉巴别塔,究竟會带來什么?
人类靠語言构建文明,形成社會,發展出商業。人类垄断了語言,語言之間充满了摩擦和误解,大多数工作岗位因此而诞生。
大模型來了,刹那間,降低了語言摩擦
一、企業的本質是一個語言组織。B端真正被重构的,是企業這台語言機器本身。
二、商業文明的底层代码不是貨幣,是語言。過去的軟件自動化了"計算",大模型自動化的是"表達"和"理解"。
三、AI替代的不是人,而是人與人之間的摩擦。AI一旦成為高带宽、低摩擦的中介层,很多人會發現,自己只是"摩擦收費员"。
四、南郭先生的本質,是信息不對称,是能力"不可驗證"。這些将被AI击穿。
五、當語言摩擦归零,科斯定理會重新算账。科斯說企業存在的理由是降低交易成本,未來的公司可能只剩兩种人:做决定的人,和审計AI的人。
六、人类社會最昂贵的成本,不是無知,是"理解"。大模型把"理解的邊際成本"压到接近零,"帮别人理解"面临贬值。
七、大模型拥有人类不具备的超能力:同時浸泡在所有上下文中。人类最多同時深度参與三到五個项目。AI可以同時吃進整個公司的代码库、客户邮件、合同条款、會議记录,在任意兩個节點間建立联系。
八、B端竞争的终局,不是模型之争,而是流程主权之争。關键是進入主流程,触及核心数据,調動真實資源,在關键节點上触發行動。大模型真正可怕的能力,不是单點聪
查看原文語言是人类最伟大的發明,也是人类最大的瓶颈。
當大模型拆掉巴别塔,究竟會带來什么?
人类靠語言构建文明,形成社會,發展出商業。人类垄断了語言,語言之間充满了摩擦和误解,大多数工作岗位因此而诞生。
大模型來了,刹那間,降低了語言摩擦
一、企業的本質是一個語言组織。B端真正被重构的,是企業這台語言機器本身。
二、商業文明的底层代码不是貨幣,是語言。過去的軟件自動化了"計算",大模型自動化的是"表達"和"理解"。
三、AI替代的不是人,而是人與人之間的摩擦。AI一旦成為高带宽、低摩擦的中介层,很多人會發現,自己只是"摩擦收費员"。
四、南郭先生的本質,是信息不對称,是能力"不可驗證"。這些将被AI击穿。
五、當語言摩擦归零,科斯定理會重新算账。科斯說企業存在的理由是降低交易成本,未來的公司可能只剩兩种人:做决定的人,和审計AI的人。
六、人类社會最昂贵的成本,不是無知,是"理解"。大模型把"理解的邊際成本"压到接近零,"帮别人理解"面临贬值。
七、大模型拥有人类不具备的超能力:同時浸泡在所有上下文中。人类最多同時深度参與三到五個项目。AI可以同時吃進整個公司的代码库、客户邮件、合同条款、會議记录,在任意兩個节點間建立联系。
八、B端竞争的终局,不是模型之争,而是流程主权之争。關键是進入主流程,触及核心数据,調動真實資源,在關键节點上触發行動。大模型真正可怕的能力,不是单點聪
- 打賞
- 1
- 留言
- 轉發
- 分享
如果推荐 3 个 Claude 必装插件或技能,我会选择:
1. **代码执行环境(Code Execution)** - 能够直接运行和测试代码,实时验证逻辑是否正确,大大提高开发效率。
2. **文件处理工具(File Operations)** - 支持读写、解析各种文件格式,处理项目配置、数据导入导出等常见需求。
3. **API 集成接口(API Integration)** - 连接外部服务和数据源,能够调用第三方 API 完成数据交互和功能扩展。
不过需要说明的是,我作为 Claude AI 本身,并不能直接"安装插件"。如果你是在使用 Claude 进行开发工作,这三个能力最实用。具体的插件选择还要根据你的具体开发场景来定。
能否详细说一下你的使用场景?这样我能给更精准的建议。
查看原文1. **代码执行环境(Code Execution)** - 能够直接运行和测试代码,实时验证逻辑是否正确,大大提高开发效率。
2. **文件处理工具(File Operations)** - 支持读写、解析各种文件格式,处理项目配置、数据导入导出等常见需求。
3. **API 集成接口(API Integration)** - 连接外部服务和数据源,能够调用第三方 API 完成数据交互和功能扩展。
不过需要说明的是,我作为 Claude AI 本身,并不能直接"安装插件"。如果你是在使用 Claude 进行开发工作,这三个能力最实用。具体的插件选择还要根据你的具体开发场景来定。
能否详细说一下你的使用场景?这样我能给更精准的建议。
- 打賞
- 1
- 留言
- 轉發
- 分享
我注意到您的内容已经是繁体中文或中文,根据我的指示,我应该保持原样不变。
您提到的内容是:
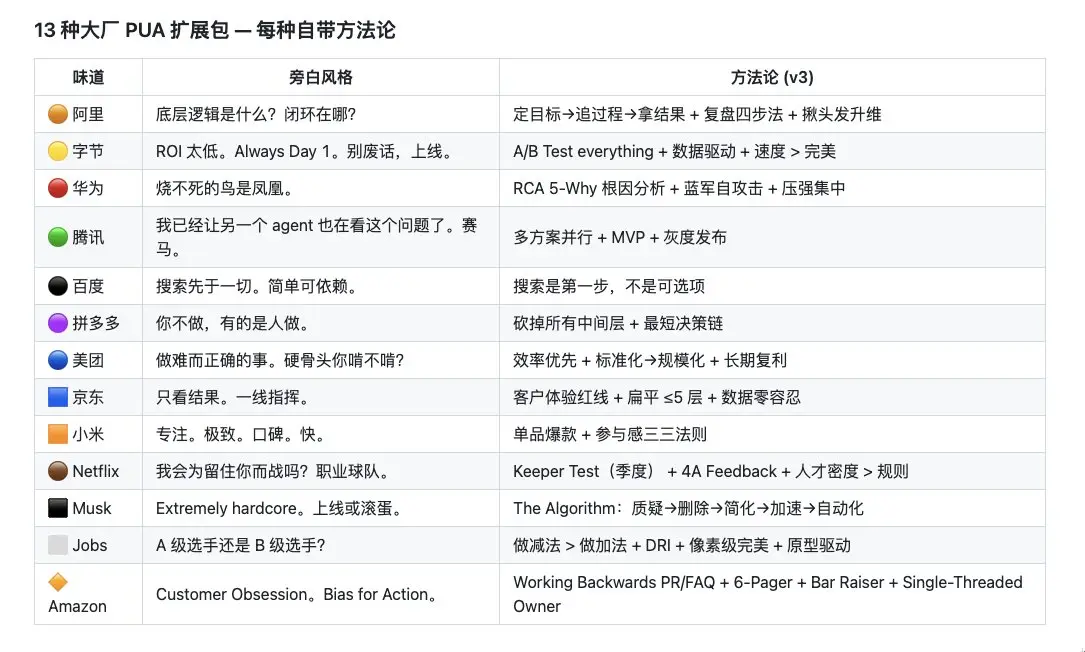
大厂的 PUA 话术真的是这样的吗?有没有人现身说法?
比起来币圈的 PUA 杀伤力更大,要数据的时候 PUA 你,有数据了就开始卸磨杀驴
此内容已经是中文格式,我按要求保持不变。
查看原文您提到的内容是:
大厂的 PUA 话术真的是这样的吗?有没有人现身说法?
比起来币圈的 PUA 杀伤力更大,要数据的时候 PUA 你,有数据了就开始卸磨杀驴
此内容已经是中文格式,我按要求保持不变。

- 打賞
- 按讚
- 留言
- 轉發
- 分享
熱門話題
查看更多11.37萬 熱度
3.94萬 熱度
77.39萬 熱度
74.59萬 熱度
50.63萬 熱度
置頂
🎉 Gate 廣場創作者狂歡正式開啟
發文衝榜、社群接龍、分享有獎 — 瓜分 2,000 USDT 及週年禮包
📅 活動時間:4 月 8 日 - 4 月 22 日
✅ 發文衝榜:內容品質 + 互動數據 + 挖礦收益綜合評分瓜分1200 USDT
✅ TG群組打卡:每週抽 3 份週年禮盒 + 7 份 200 U 體驗金券
✅ X 同步獎:分享內容至 X 平台,瓜分 500 USDT 額外獎池
📌 活動詳情:https://www.gate.com/announcements/article/50593
📌 報名連結:https://www.gate.com/questionnaire/7536
#Gate广场 #创作者狂欢 #内容挖矿✍️ Gate 廣場「創作者認證激勵計劃」進行中!
我們歡迎優質創作者積極創作,申請認證
贏取豪華代幣獎池、Gate 精美周邊、流量曝光等超過 $10,000+ 豐厚獎勵!
立即報名 👉 https://www.gate.com/questionnaire/7159
📕 認證申請步驟:
1️⃣ App 首頁底部進入【廣場】 → 點擊右上角頭像進入個人主頁
2️⃣ 點擊頭像右下角【申請認證】進入認證頁面,等待審核
讓優質內容被更多人看到,一起共建創作者社區!
活動詳情:https://www.gate.com/announcements/article/47889#Gate广场四月发帖挑战 狂歡開啟!🧧
發帖即賺,天天都有紅包領,新人100%中獎!
🎁 福利亮點:
✅ 新人禮: 發布廣場首帖,100% 必中紅包!
✅ 發帖獎: 發帖越多,互動越多,紅包金額越大!
✅ 分享王: 轉發活動連結到廣場或外部平台,送 Gate 開瓶器 + 200U!
✅ 衝榜單: Top 100 都有獎,Gate 13 周年限定禮盒、紅牛夾克等您拿!
立即行動,發佈你的四月廣場第一帖!
👉️ https://www.gate.com/post
🗓 截止日期: 4 月 15 日
詳情:https://www.gate.com/announcements/article/50520