Вступ
У першому уроці ми розглянули, чому ШІ стає новою інфраструктурою для торгівлі криптовалютою. Головне питання: як би не був потужний ШІ, він працює лише в межах даних, які Ви надаєте.
Більшість стратегій зазнають невдачі не через надмірну простоту моделі, а через напрямні помилки на рівні даних: недостатню якість, викривлений дизайн ознак або упереджені методи перевірки.
Тому реальна торгівля із ШІ починається не з “вибору моделі”, а з “побудови основи даних”. Те, що Ви подаєте моделі, визначає її можливості; те, що вона бачить, визначає її рішення.
1. Спочатку досягайте консенсусу: більше даних не завжди краще — дані з причинною структурою ефективніші
Трейдери, які вперше працюють із ШІ, часто схильні до “накопичення даних”: збирають усе, вважаючи, що більше ознак спростить пошук Alpha.
Насправді дані низької якості, шумні, слабко корельовані, знижують стабільність моделі. Причина проста:
- Модель навчається хибних патернів через шум
- При зміні позазразкового середовища хибні патерни першими виходять із ладу
- Чим більше зайвих ознак, тим складніше пояснювати та підтримувати стратегію
Перший принцип побудови системи даних:
Обирайте дані навколо торгових задач — не шукайте задачі навколо даних.
Якщо Ви вирішуєте задачу “прогнозу короткострокового напрямку”, пріоритет — мікроструктура та шоки настроїв; якщо працюєте над “керуванням середньостроковими позиціями”, зосередьтеся на ліквідності, структурі волатильності та макро-факторах.
2. Чотири основні джерела даних для ШІ-торгівлі криптовалютою
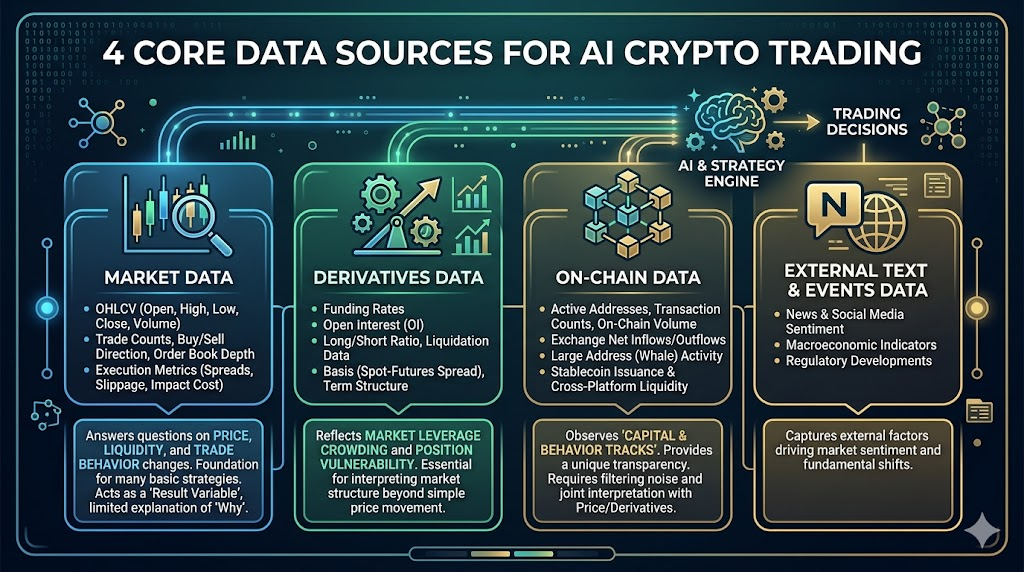
У крипторинках найцінніші дані зазвичай надходять з чотирьох рівнів: ринкові дані, деривативи, ончейн та зовнішня інформація.
Ринкові дані
Це основа для всіх стратегій, включаючи:
- OHLCV (Open, High, Low, Close, Volume)
- Кількість угод, напрямок купівлі/продажу, глибина книги ордерів
- Спред, прослизання, індикатори вартості виконання
Відповідає на питання: як змінюються ціни, ліквідність, поведінка торгівлі.
Багато базових стратегій можна побудувати лише на ринкових даних, але їх обмеження: це радше “змінна результату”, з обмеженою пояснювальною силою щодо “чому відбуваються зміни”.
Дані деривативів
Особливо важливі для крипторинків, включаючи:
- Ставка фінансування
- Відкритий інтерес
- Співвідношення лонг/шорт акаунтів, дані ліквідації
- Базис (різниця ціни спот-контракту), структура терміну
Ці дані відображають скупчення кредитного плеча та вразливість позицій.
Наприклад, “зростання ціни + зростання відкритого інтересу + висока ставка фінансування” проти “зростання ціни + падіння відкритого інтересу” означають різне. Перше може сигналізувати про посилення тренду чи скупчення кредитного плеча; друге ймовірніше зумовлене покриттям шортів.
Без виміру деривативів складно оцінити структуру позицій за рухами ринку.
Ончейн-дані
Ключова перевага, що відрізняє крипторинки від традиційних, включає:
- Активні адреси, кількість транзакцій, обсяг ончейн-переказів
- Чистий притік/відтік на біржі
- Дії великих адрес (whale)
- Випуск стейблкоїнів та міжплатформені потоки
Цінність ончейн-даних — у спостереженні за траєкторіями капіталу та поведінки, але складність — у затримці інтерпретації та фільтрації шуму.
Наприклад, збільшення притоку на біржу може означати підготовку до продажу або хеджування. Ончейн-дані слід трактувати разом із структурою цін і даними деривативів — використання лише їх легко призводить до хибних рішень.
Зовнішні текстові та подієві дані (Новини/Соціальні/Макро)
Включають новини, обговорення у соцмережах, події політики, часи публікації макро-даних.
Це радше джерела шоку: пояснюють, чому волатильність раптово зростає або тренди короткочасно змінюються.
Такий тип даних має очевидні проблеми: дуже суб’єктивні, шумні, змішані правдиві та хибні дані.
Зовнішній текст краще використовувати як фактори попередження ризику та фільтри подій, не рекомендується як єдиний сигнал входу.
3. Від сирих даних до торгованих ознак: інженерія ознак — реальний роздільник стратегій
ШІ не розуміє ринкових наративів напряму; він розпізнає лише патерни ознак.
Другий крок — не поспішати тренувати моделі, а трансформувати сирі дані у навчені, перевірені, торговані ознаки.
Поширені корисні ознаки можна згрупувати у чотири категорії:
- Трендові ознаки: імпульс, нахил ковзної середньої, сила прориву
- Ознаки волатильності: історична волатильність, амплітуда діапазону, стрибки волатильності
- Структурні ознаки: відхилення ставки фінансування, темп зміни відкритого інтересу, зміна базису
- Поведінкові ознаки: зміни чистого ончейн-потоку, шоки настроїв у новинах, аномальна активність у соцмережах
Важливі не “яскраві ознаки”, а три критерії:
- Чи мають економічне значення (не лише математична комбінація)
- Чи доступні в реальному часі (без майбутньої інформації)
- Чи зберігають стійкість у різних фазах ринку (bull/bear/консолідація без надмірних спотворень)
4. Дизайн міток: те, що Ви просите модель прогнозувати, визначає, чого вона навчається
Багато хто за замовчуванням просить модель прогнозувати “наступну K-лінію вверх/вниз”, але це не завжди оптимально.
Торгові цілі можуть мати різні форми міток:
- Класифікаційні мітки: чи перевищує майбутній n-періодний дохід поріг
- Регресійні мітки: майбутній n-періодний дохід
- Мітки ризику: чи трапляється велике просідання у майбутні n періодів
- Структурні мітки: чи розширюється волатильність або ставка фінансування стає екстремальною у майбутньому
Якщо Ваша стратегія — уникати великих просідань, а Ви використовуєте короткостроковий напрямок ціни як мітку, навіть дуже точна модель може бути не корисною.
Мітки повинні відповідати цілям стратегії: який прибуток Ви шукаєте в торгівлі, таку ціль має вивчати модель.
5. Ключ до перевірки даних: у світі часових рядів методи перевірки важливіші за моделі
У типових задачах машинного навчання випадкове перемішування навчальних і тестових наборів є поширеним і обґрунтованим; але в торгівлі це викликає серйозне спотворення.
Ринки мають структуру залежності від часу — майбутня інформація ніколи не повинна просочуватися у минуле.
Торгівля із ШІ повинна дотримуватися мінімум трьох правил перевірки:
- Розділяйте навчання, перевірку та тестування за часом — не випадковим перемішуванням
- Позазразкова перевірка повинна охоплювати різні середовища волатильності
- Використовуйте ковзне вікно (walk-forward) для моделювання реального розгортання
Багато “стратегій-чудес у бектесті” розвалюються не через погіршення ринку, а через оптимістичні упередження у методах тестування з самого початку.
6. П’ять типових пасток даних
Look-ahead bias
Використання недоступних на момент часу даних призводить до завищених результатів.
Survivorship bias
Навчання лише на монетах або платформах, що вижили, ігнорування невдалих зразків.
Over-cleaning
Видалення реального шуму як брудних даних — модель втрачає адаптивність до екстремальних ринків.
Feature leakage
Ознаки неявно містять інформацію мітки — модель здається надто точною.
Frequency mismatch
Вимушене використання низькочастотних ончейн-ознак у високочастотних торгових задачах — виникають хибні сигнали.
Ці проблеми не виникають під час бектестування, але швидко посилюються у реальній торгівлі.
Практичний робочий процес із даними: почніть з малого й стабільного, потім розширюйте
Для учнів курсу найбезпечніший підхід — не починати з мега-моделі з усіма факторами ринку, а розпочати з мінімально життєздатного фреймворку даних:
- Обирайте один актив (наприклад, BTC або ETH)
- Починайте з типів даних ринку та деривативів
- Створіть 10–20 базових ознак з економічним змістом
- Сформуйте чітку мітку (наприклад, чи майбутній 4-годинний дохід >0)
- Перевірка часових рядів та ковзний тест
- Поступово додавайте ончейн- та текстові фактори
Такий підхід забезпечує чітку локалізацію проблем, низькі витрати на ітерацію та короткий шлях до розгортання.
Складні системи не створюються одразу — вони розширюються шар за шаром від інтерпретованих малих систем.
Справжнє значення Gate for AI на рівні даних
У реальній реалізації етап даних часто займає найбільше часу: збір із різних джерел, очищення формату, синхронізація часу, побудова конвеєрів ознак, інтеграція стратегій.
Саме тому платформні ШІ-інструменти стають дедалі важливішими. Gate for AI як приклад такої інфраструктури — цінність не у створенні універсальної стратегії для Вас, а у допомозі трейдерам ефективно завершувати інженерний цикл від даних до стратегії та знижувати тертя між дослідженням і виконанням. Трейдери все одно мають визначати задачі, встановлювати обмеження, керувати ризиками — але базові робочі процеси можуть бути більш стандартизованими та повторюваними.






