Введение
В занятии 1 мы рассмотрели, почему ИИ становится новой инфраструктурой для криптотрейдинга. Важно понимать: насколько бы мощным ни был ИИ, он ограничен только теми данными, которые вы ему предоставляете.
Многие торговые стратегии терпят неудачу не из-за простоты модели, а из-за ошибок на уровне данных: недостаточное качество, искажение признаков или предвзятые методы проверки.
Поэтому реальная торговля с ИИ начинается не с «выбора модели», а с «создания базы данных». Какие данные вы подаёте в модель, то она и сможет анализировать. То, что она видит, определяет её решения.
1. Сформируйте консенсус: больше данных — не всегда лучше, важнее причинно-следственная структура
Трейдеры, только начинающие работать с ИИ, часто стремятся собрать максимум данных, считая, что больше признаков упростит поиск alpha.
На деле низкокачественные, шумные и слабо связанные данные только снижают устойчивость модели. Причина очевидна:
- Модель учится ложным паттернам на шуме
- При изменении рыночных условий вне выборки ложные паттерны исчезают первыми
- Чем больше избыточных признаков, тем сложнее объяснять и поддерживать стратегию
Первый принцип построения системы данных:
Выбирайте данные, исходя из задач трейдинга, а не подбирайте задачи к имеющимся данным.
Если вы решаете задачу «прогноза краткосрочного направления», фокусируйтесь на микроструктуре и шоках настроения. Для «среднесрочного управления позицией» уделяйте внимание ликвидности, структуре волатильности и макрофакторам.
2. Четыре основных источника данных для ИИ-криптотрейдинга
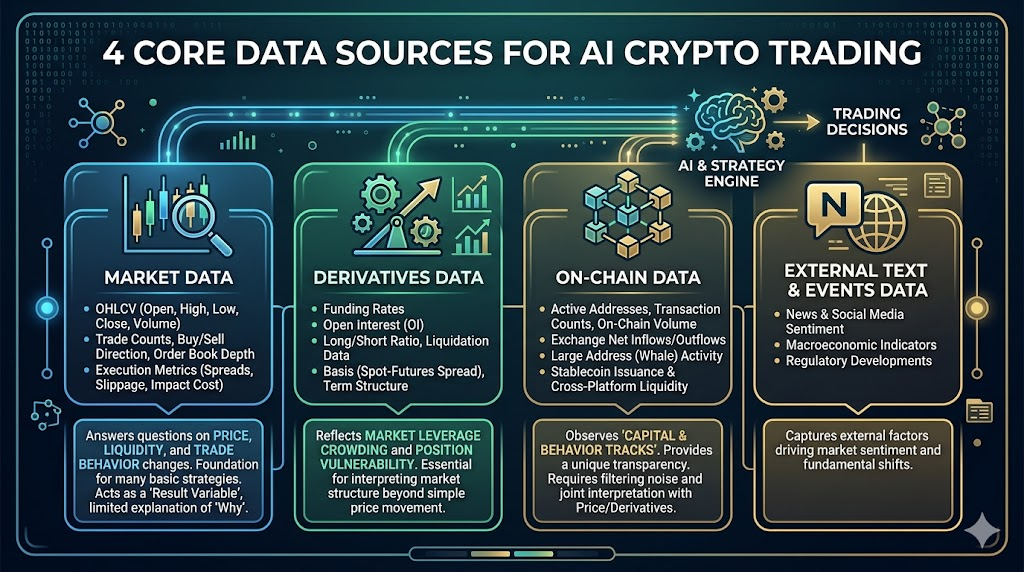
В крипторынках наиболее ценные данные обычно поступают из четырёх источников: рыночные данные, деривативы, ончейн и внешняя информация.
Рыночные данные
Это основа всех стратегий, включает:
- OHLCV (открытие, максимум, минимум, закрытие, объём)
- Количество сделок, направление покупки/продажи, глубина Книги Ордеров
- Спред, проскальзывание, показатели стоимости исполнения
Эти данные показывают, как меняются цены, ликвидность и поведение трейдеров.
На одних рыночных данных можно построить базовые стратегии, но их ограничение — это скорее «результат», слабо объясняющий причины изменений.
Данные по деривативам
В крипторынках особенно важны:
- Ставка Финансирования
- Открытый Интерес
- Соотношение лонг/шорт, данные по Ликвидации
- Основа (разница между ценой спота и контракта), структура сроков
Они отражают концентрацию плеча и уязвимость позиций на рынке.
Например, «рост цены + рост открытого интереса + высокая ставка финансирования» и «рост цены + падение открытого интереса» имеют разную природу. Первый вариант может означать усиление тренда или перегруженность плеча, второй — чаще связан с покрытием шортов.
Без данных по деривативам сложно понять структуру позиций за движением рынка.
Ончейн-данные
Это главное отличие крипторынков от традиционных:
- Активные адреса, количество транзакций, объём ончейн-переводов
- Чистый приток/отток на биржи
- Действия крупных адресов (китов)
- Выпуск стейблкоинов и кроссплатформенные потоки
Ончейн-данные позволяют отслеживать «капитальные и поведенческие траектории», но их сложно быстро интерпретировать и очистить от шума.
Например, рост притока на биржу может означать как подготовку к продаже, так и к хеджированию. Ончейн-данные нужно анализировать вместе с ценовыми и деривативными показателями — их отдельное использование приводит к ошибкам.
Внешние текстовые и событийные данные (новости/соцсети/макро)
Сюда входят новости, активность обсуждений в соцсетях, политические события, время публикации макроэкономических данных.
Это «данные источника шока»: объясняют, почему резко изменилась волатильность или краткосрочно сменился тренд.
Такие данные имеют очевидные недостатки: субъективность, высокий шум, смешение правдивой и ложной информации.
Внешние тексты лучше использовать как «фильтры событий» и «факторы оповещения о рисках», а не как единственный источник сигналов.
3. От сырых данных к торговым признакам: Feature Engineering — ключевой этап разделения стратегий
ИИ не понимает рыночные истории, он распознаёт только паттерны признаков.
Второй шаг — не обучение моделей, а преобразование сырых данных в обучаемые, проверяемые и пригодные для торговли признаки.
Полезные признаки делятся на четыре группы:
- Трендовые: импульс, наклон скользящей средней, сила пробоя
- Волатильностные: историческая волатильность, диапазон, скачки волатильности
- Структурные: отклонение ставки финансирования, скорость изменения открытого интереса, изменение основы
- Поведенческие: изменения чистого ончейн-потока, шоки новостного настроения, аномальная активность соцсетей
Главное — не «яркость признаков», а соответствие трём критериям:
- Экономический смысл (не просто математическая комбинация)
- Доступность в реальном времени (без будущей информации)
- Стабильность в разных рыночных фазах (булл/медвежий/консолидация без сильных искажений)
4. Дизайн меток: что вы просите модель предсказывать, то она и будет изучать
Многие по умолчанию заставляют модель прогнозировать «следующее движение свечи», но это не всегда оптимально.
Цели стратегии могут оформляться разными метками:
- Классификация: превышает ли будущая доходность за n периодов пороговое значение
- Регрессия: будущая доходность за n периодов
- Риск: возникнет ли крупная просадка за n периодов
- Структура: расширится ли волатильность или станет ли ставка финансирования экстремальной
Если ваша цель — «избежать крупных просадок», а вы используете метку «краткосрочное направление цены», даже точная модель не даст результата.
Метки должны соответствовать целям стратегии: какую прибыль вы хотите получить, тому и должна обучаться модель.
5. Ключ к валидации данных: в мире временных рядов методы валидации важнее моделей
В стандартных задачах машинного обучения случайное перемешивание обучающей и тестовой выборки допустимо, но в трейдинге это приводит к искажениям.
Потому что рынки имеют временную структуру — нельзя допускать утечку будущей информации в прошлое.
ИИ-трейдинг требует соблюдения трёх базовых правил валидации:
- Разделять обучение, валидацию и тест по времени, а не случайно
- Валидация вне выборки должна охватывать разные режимы волатильности
- Использовать скользящее окно (walk-forward) для имитации реального внедрения
Многие «чудо-стратегии» рушатся не из-за ухудшения рынка, а из-за изначально оптимистичных методов тестирования.
6. Пять типичных ловушек при работе с данными
Look-ahead bias
Использование данных, которые не были доступны в момент сделки, приводит к завышенным результатам.
Survivorship bias
Обучение только на выживших монетах или платформах — игнорируются неудачные примеры.
Избыточная очистка
Удаление реального шума как грязных данных — модель теряет адаптивность к экстремальным рынкам.
Feature leakage
Признаки неявно содержат информацию о метке — модель кажется слишком точной.
Frequency mismatch
Использование низкочастотных ончейн-признаков для высокочастотных торговых задач приводит к ложным сигналам.
Эти ошибки не видны на тестах на истории, но быстро проявляются в реальной торговле.
Практический рабочий процесс с данными: начните с малого и устойчивого, затем расширяйте
Для учащихся курса наиболее безопасно не строить сразу «мегамодель на все факторы по всему рынку», а начать с минимального жизнеспособного фреймворка данных:
- Выберите один актив (например, BTC или ETH)
- Начните с рыночных и деривативных данных
- Постройте 10–20 базовых признаков с экономическим смыслом
- Разработайте чёткую метку (например, будет ли доходность за следующие 4 часа >0)
- Валидация временных рядов и скользящее тестирование
- Постепенно добавляйте ончейн- и текстовые факторы
Такой подход позволяет чётко локализовать проблему, снизить издержки на итерации и ускорить внедрение.
Сложные системы строятся не сразу — они растут слой за слоем из небольших интерпретируемых систем.
Реальная значимость Gate for AI на уровне данных
На практике этап работы с данными — самый трудоёмкий: сбор из разных источников, очистка, выравнивание по времени, построение пайплайнов признаков, интеграция в стратегию.
Поэтому платформенные инструменты ИИ становятся всё важнее. Gate for AI — пример такой инфраструктуры: его ценность не в «генерации универсальной стратегии», а в эффективной организации полного инженерного цикла от данных к стратегии и снижении трения между исследованием и исполнением. Трейдеру всё равно нужно формулировать задачи, определять ограничения, управлять рисками, но базовые процессы становятся стандартизированными и повторно используемыми.





