Introdução
Na Lição 1, analisou-se por que motivo a IA está a tornar-se a nova infraestrutura da negociação de criptomoedas. A questão central que se segue é: independentemente do poder da IA, esta só consegue operar dentro dos limites dos dados fornecidos.
Muitas estratégias falham não porque o modelo seja demasiado simples, mas devido a erros direcionais ao nível dos dados: quer por insuficiência de qualidade, distorção no desenho das variáveis ou enviesamento nos métodos de validação.
Assim, a negociação real com IA raramente começa por “escolher um modelo”, mas sim por “construir a base de dados”. O que for fornecido ao modelo determina o que este pode observar; aquilo que observa determina os julgamentos que é capaz de formular.
1. Estabelecer consenso antes de mais: mais dados não é sempre melhor—dados com estrutura causal são preferíveis
Negociadores inexperientes em IA tendem a adotar uma mentalidade de “acumulação de dados”: recolher toda a informação possível, acreditando que mais variáveis facilitam a descoberta de alpha.
Na prática, dados de baixa qualidade, ruidosos e fracamente correlacionados reduzem a estabilidade do modelo. A razão é simples:
- O modelo “aprende padrões falsos” a partir do ruído
- Quando o ambiente fora da amostra muda, esses padrões são os primeiros a falhar
- Quanto mais redundantes forem as variáveis, mais difícil é explicar e manter a estratégia
O princípio fundamental para construir um sistema de dados é:
Selecionar dados em função dos problemas de negociação—não procurar problemas nos próprios dados.
Se o objetivo for resolver a “previsão da direção no curto prazo”, dar prioridade à microestrutura e a choques de sentimento; se for “gestão de posições no médio prazo”, focar mais em liquidez, estrutura de volatilidade e fatores macroeconómicos.
2. Quatro fontes essenciais de dados para negociação de criptomoedas com IA
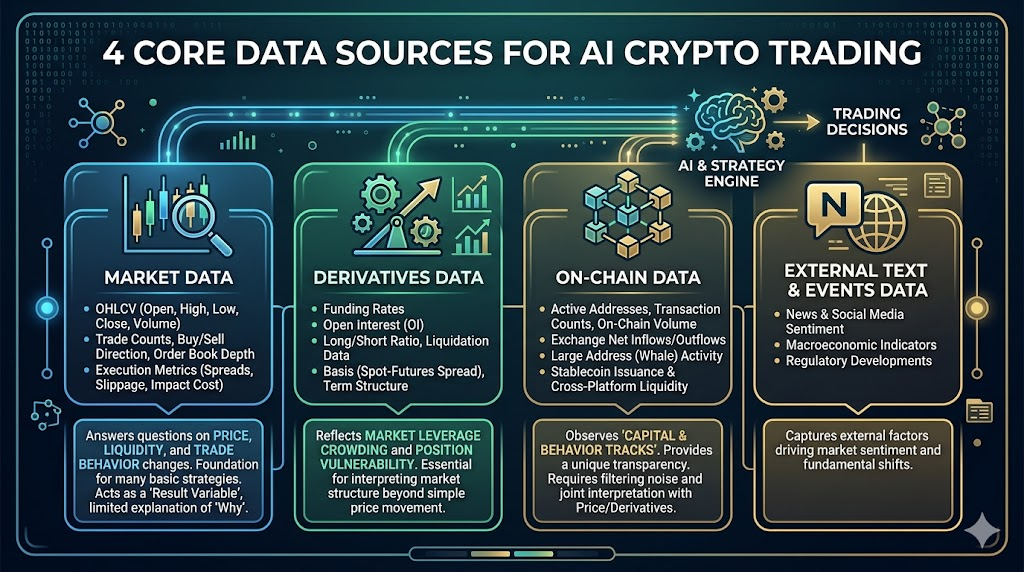
No mercado de criptomoedas, os dados mais valiosos provêm geralmente de quatro camadas: dados de mercado, derivados, on-chain e informação externa.
Dados de mercado
Esta é a camada fundamental para todas as estratégias, incluindo:
- OHLCV (Open, High, Low, Close, Volume)
- Número de negociações, direção de compra/venda, profundidade do livro de ordens
- Spread, derrapagem, indicadores de custo de execução
Permite compreender: como variam os preços, como evolui a liquidez, como muda o comportamento de negociação.
Muitas estratégias básicas podem ser construídas apenas com dados de mercado, mas a sua limitação é: funciona mais como “variável de resultado”, com capacidade explicativa limitada para o “porquê das alterações”.
Dados de derivados
Especialmente relevantes nos mercados de criptomoedas, incluindo:
- Taxa de financiamento
- Juros em aberto
- Rácio de contas long/short, dados de liquidação
- Base (diferença entre preço à vista e contrato), estrutura temporal
Estes dados refletem a concentração de alavancagem no mercado e a vulnerabilidade das posições.
Por exemplo, “subida de preço + aumento de OI + taxa de financiamento elevada” vs. “subida de preço + diminuição de OI” têm significados completamente distintos. O primeiro pode indicar reforço da tendência ou concentração de alavancagem; o segundo é mais provável resultar de short covering.
Sem a dimensão dos derivados, é difícil avaliar a estrutura das posições por trás dos movimentos do mercado.
Dados on-chain
Uma vantagem essencial que distingue os mercados de criptomoedas dos tradicionais, incluindo:
- Endereços ativos, número de transações, volume de transferências on-chain
- Fluxo líquido de entrada/saída nas exchanges
- Comportamento de grandes endereços (baleias)
- Emissão de stablecoin e fluxos entre plataformas
O valor dos dados on-chain reside na observação de “trajetórias de capital e comportamento”, mas o desafio é a interpretação tardia e a filtragem do ruído.
Por exemplo, um aumento do fluxo de entrada numa exchange pode indicar preparação para venda ou cobertura. Os dados on-chain devem ser analisados juntamente com a estrutura de preços e os dados de derivados—isoladamente, conduzem facilmente a erros de avaliação.
Dados externos de texto e eventos (notícias/social/macro)
Incluem notícias, intensidade de discussão em redes sociais, eventos políticos e timings de divulgação de dados macroeconómicos.
Funcionam sobretudo como “dados de fonte de choque”: explicam porque é que a volatilidade dispara subitamente ou as tendências mudam temporariamente.
No entanto, este tipo de dados apresenta problemas evidentes: são altamente subjetivos, ruidosos e misturam informação verdadeira e falsa.
Por isso, o texto externo é mais adequado como “fator de alerta de risco” e “filtro de eventos”, não sendo recomendado como sinal de entrada isolado.
3. Dos dados brutos às variáveis negociáveis: feature engineering é o verdadeiro divisor estratégico
A IA não compreende diretamente “narrativas de mercado”; reconhece apenas padrões de variáveis.
Por isso, o segundo passo não é apressar o treino de modelos, mas transformar os dados brutos em variáveis aprendíveis, verificáveis e negociáveis.
As principais variáveis úteis agrupam-se em quatro categorias:
- Variáveis de tendência: impulso, inclinação da média móvel, força de breakout
- Variáveis de volatilidade: volatilidade histórica, amplitude da gama, saltos de volatilidade
- Variáveis estruturais: desvio da taxa de financiamento, taxa de variação do OI, variação da base
- Variáveis comportamentais: alterações no fluxo líquido on-chain, choques de sentimento em notícias, intensidade anómala em redes sociais
O essencial não são “variáveis vistosas”, mas sim três critérios:
- Significado económico (não apenas combinação matemática)
- Disponibilidade em tempo real (sem informação futura)
- Persistência em diferentes fases de mercado (bull/bear/lateralização sem distorção excessiva)
4. Designação de labels: o que se pede ao modelo para prever determina o que aprende
Muitas pessoas assumem que o modelo deve prever “a próxima vela K para cima/baixo”, mas isso nem sempre é a melhor abordagem.
Os objetivos de negociação podem assumir várias formas de labels:
- Labels de classificação: se o retorno futuro em n períodos excede determinado limiar
- Labels de regressão: retorno futuro em n períodos
- Labels de risco: se ocorre uma grande redução em n períodos futuros
- Labels estruturais: se a volatilidade expande ou a taxa de financiamento se torna extrema no futuro
Se o objetivo da estratégia for “evitar grandes reduções” mas se usar “direção do preço no curto prazo” como label, por muito preciso que seja o modelo, pode não ser útil.
Por isso, os labels devem corresponder aos objetivos da estratégia: qualquer que seja o lucro pretendido, o modelo deve aprender esse alvo.
5. O segredo da validação de dados: no universo das séries temporais, os métodos de validação importam mais do que os modelos
Em tarefas típicas de machine learning, é comum baralhar aleatoriamente os conjuntos de treino e teste; mas na negociação isto causa distorções graves.
Os mercados apresentam estrutura dependente do tempo—informação futura nunca pode “vazar” para o passado.
A negociação com IA deve cumprir três regras essenciais de validação:
- Dividir treino/validação/teste por períodos temporais—não aleatoriamente
- A validação fora da amostra deve abranger diferentes ambientes de volatilidade
- Utilizar janela móvel (walk-forward) para simular a implementação real
Muitas “estratégias milagrosas em backtest” colapsam não porque o mercado piore, mas porque os métodos de teste estavam enviesados desde o início.
6. Cinco armadilhas comuns nos dados
Look-ahead bias
Utilizar dados indisponíveis no momento leva a resultados artificialmente inflacionados.
Survivorship bias
Treinar apenas com moedas ou plataformas sobreviventes—ignorando amostras falhadas.
Limpeza excessiva
Eliminar ruído real como se fosse dados sujos—o modelo perde capacidade de adaptação a mercados extremos.
Feature leakage
Variáveis contêm implicitamente informação dos labels—fazendo o modelo parecer excessivamente preciso.
Frequency mismatch
Forçar variáveis on-chain de baixa frequência em tarefas de negociação de alta frequência—gerando sinais falsos.
Estes problemas não se manifestam durante o backtest, mas ampliam-se rapidamente na negociação em direto.
Um workflow prático de dados: começar pequeno e estável, depois expandir
Para os aprendizes do curso, a abordagem mais segura não é começar com um “mega-modelo de todos os fatores do mercado”, mas sim com uma estrutura mínima viável de dados:
- Escolher um único ativo (como BTC ou ETH)
- Começar com dados de mercado e derivados
- Criar 10–20 variáveis básicas com significado económico
- Definir um label claro (por exemplo, se o retorno futuro em 4 horas >0)
- Validação em séries temporais e teste com janela móvel
- Adicionar gradualmente fatores on-chain e de texto
Este método mantém a identificação dos problemas clara, custos de iteração baixos e um percurso de implementação curto.
Sistemas complexos não se constroem de uma só vez—crescem camada a camada, a partir de sistemas pequenos e interpretáveis.
A verdadeira importância da Gate for AI na camada de dados
Na implementação prática, a fase de dados é frequentemente a mais demorada: recolha multi-fonte, limpeza de formatos, alinhamento temporal, pipelines de variáveis, integração de estratégias.
Por isso, as ferramentas de IA baseadas em plataforma tornam-se cada vez mais relevantes. Tomando a Gate for AI como exemplo dessa infraestrutura—o valor não está em “gerar uma estratégia universal”, mas em ajudar negociadores a completar de forma eficiente o ciclo de engenharia dos dados à estratégia e a reduzir a fricção entre investigação e execução. Os negociadores continuam a definir problemas, impor restrições, gerir riscos—mas os workflows subjacentes podem tornar-se mais padronizados e reutilizáveis.