Introdução
Na Aula 1, apresentamos por que a IA está se consolidando como a nova infraestrutura para negociação de cripto. A principal questão que surge é: por mais avançada que seja a IA, ela só opera dentro dos limites dos dados fornecidos.
Muitas estratégias não fracassam pela simplicidade do modelo, mas sim por erros direcionais na camada de dados: seja pela baixa qualidade, distorção no design das features ou métodos de validação enviesados.
Por isso, a negociação com IA não começa pela “escolha do modelo”, mas sim pela “construção da base de dados”. O que você alimenta no modelo determina o que ele enxerga; e o que ele enxerga define os julgamentos que pode realizar.
1. Estabeleça um consenso: mais dados nem sempre é melhor — dados com estrutura causal são superiores
Traders iniciantes em IA frequentemente caem no vício do “acúmulo de dados”: coletam tudo que conseguem, acreditando que mais features facilitam encontrar alpha.
Na prática, dados de baixa qualidade, ruidosos e pouco correlacionados reduzem a estabilidade do modelo. O motivo é simples:
- O modelo aprende padrões falsos a partir do ruído
- Quando o ambiente fora da amostra muda, esses padrões falsos são os primeiros a falhar
- Quanto mais features redundantes, mais difícil explicar e manter a estratégia
O primeiro princípio para construir um sistema de dados é:
Selecionar dados a partir dos problemas de negociação — não buscar problemas a partir dos dados.
Se o objetivo é “prever direção de curto prazo”, priorize microestrutura e choques de sentimento; para “gestão de posições no médio prazo”, foque em liquidez, estrutura de volatilidade e fatores macroeconômicos.
2. Quatro principais fontes de dados para negociação de cripto com IA
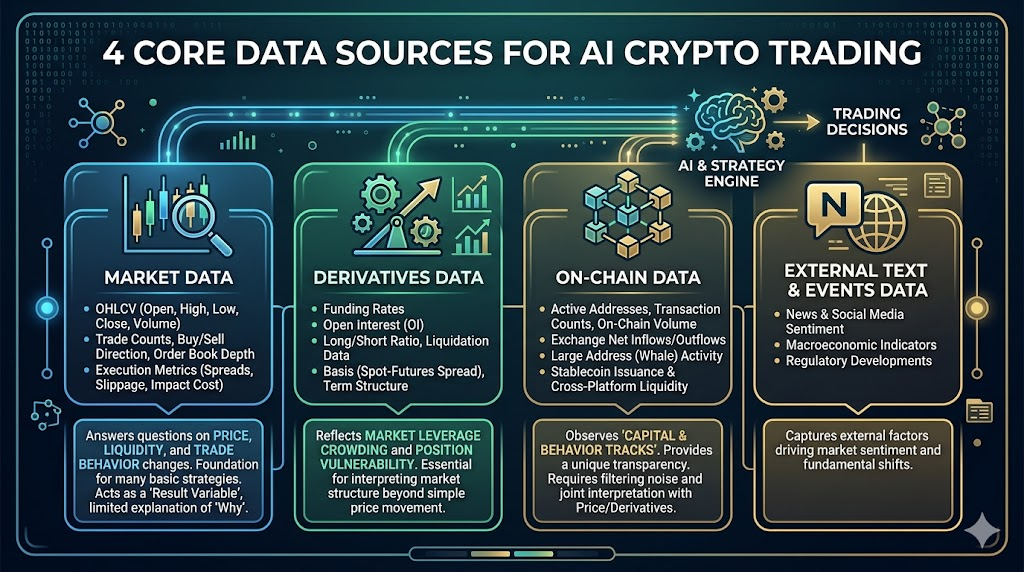
No mercado de cripto, os dados mais relevantes geralmente se originam de quatro camadas: dados de mercado, derivativos, on-chain e informações externas.
Dados de mercado
Esta é a base de todas as estratégias, incluindo:
- OHLCV (abertura, máxima, mínima, fechamento, volume)
- Número de negociações, direção de compra/venda, profundidade do livro de ordens
- Spread, slippage, indicadores de custo de execução
Esses dados respondem: como os preços variam, como a liquidez se altera e como muda o comportamento de negociação.
É possível construir estratégias básicas apenas com dados de mercado, mas sua limitação está no fato de ser uma “variável de resultado”, com pouco poder explicativo sobre as razões das mudanças.
Dados de derivativos
Essenciais no universo cripto, incluindo:
- Taxa de fundos
- Juros em aberto
- Proporção de contas long/short, dados de liquidação
- Basis (diferença entre preço spot e contrato), estrutura de prazos
Esses dados refletem o crowding da alavancagem e a vulnerabilidade das posições no mercado.
Por exemplo, “preço subindo + OI subindo + taxa de fundos alta” versus “preço subindo + OI caindo” indicam situações completamente diferentes. O primeiro pode sugerir fortalecimento de tendência ou crowding de alavancagem; o segundo é mais associado a short covering.
Sem a dimensão dos derivativos, é difícil entender a estrutura de posições por trás dos movimentos do mercado.
Dados on-chain
Um diferencial fundamental do mercado de cripto em relação ao tradicional, incluindo:
- Endereços ativos, número de transações, tamanho das transferências on-chain
- Fluxo líquido nas exchanges
- Comportamento de grandes endereços (baleias)
- Emissão de stablecoins e fluxos entre plataformas
O valor dos dados on-chain está em mapear “trajetórias de capital e comportamento”, mas o desafio está na interpretação tardia e no filtro de ruído.
Por exemplo, o aumento do fluxo para exchanges pode indicar preparação para venda ou hedge. Dados on-chain devem ser analisados em conjunto com a estrutura de preços e dados de derivativos — o uso isolado leva facilmente a erros de julgamento.
Dados externos de texto e eventos (notícias/social/macro)
Incluem notícias, volume de discussões em redes sociais, eventos de política e divulgação de dados macroeconômicos.
Funcionam como “fontes de choque”: explicam por que a volatilidade dispara ou tendências mudam de forma pontual.
No entanto, esse tipo de dado apresenta desafios: é altamente subjetivo, ruidoso e mistura informações verdadeiras e falsas.
Por isso, textos externos servem melhor como “fatores de alerta de risco” e “filtros de eventos”, não sendo recomendados como sinais de entrada isolados.
3. De dados brutos a features negociáveis: feature engineering é o verdadeiro divisor de estratégias
A IA não interpreta “narrativas de mercado”; ela identifica padrões em features.
O segundo passo, portanto, não é treinar modelos imediatamente, mas transformar dados brutos em features que sejam aprendíveis, verificáveis e negociáveis.
As features mais úteis costumam se agrupar em quatro categorias:
- Tendência: momento, inclinação da média móvel, força de breakout
- Volatilidade: volatilidade histórica, amplitude do intervalo, saltos de volatilidade
- Estruturais: desvio da taxa de fundos, taxa de variação do OI, mudança de basis
- Comportamentais: mudanças de fluxo líquido on-chain, choques de sentimento em notícias, aquecimento anormal em redes sociais
O ponto-chave não são “features chamativas”, mas sim três critérios:
- Possuem significado econômico (não apenas combinação matemática)
- Podem ser obtidas em tempo real (sem informação futura)
- Persistem em diferentes fases do mercado (alta/baixa/lateralidade sem distorção excessiva)
4. Design de label: o que você pede para o modelo prever determina o que ele aprende
Muitos assumem que o modelo deve prever “se a próxima K-line sobe ou cai”, mas isso nem sempre é o ideal.
Os objetivos de negociação podem assumir diversas formas de labels:
- Classificação: se o retorno futuro em n períodos supera um limite
- Regressão: retorno futuro em n períodos
- Risco: se ocorre grande drawdown nos próximos n períodos
- Estrutural: se a volatilidade expande ou a taxa de fundos se torna extrema no futuro
Se o objetivo da estratégia é “evitar grandes drawdowns” mas a label é “direção de preço de curto prazo”, não importa a precisão do modelo, ele pode ser pouco útil.
Portanto, as labels precisam estar alinhadas ao objetivo da estratégia: o lucro que você busca na negociação é o que o modelo deve aprender como alvo.
5. O segredo da validação de dados: em séries temporais, o método de validação é mais importante do que o modelo
Em machine learning tradicional, embaralhar conjuntos de treino e teste é comum e aceitável; mas em negociação isso gera distorções graves.
Isso porque os mercados têm estrutura dependente do tempo — informações futuras nunca podem vazar para o passado.
A negociação com IA deve seguir ao menos três regras de validação:
- Separar treino, validação e teste por tempo — nunca por embaralhamento aleatório
- A validação fora da amostra deve abranger diferentes ambientes de volatilidade
- Utilize janela móvel (walk-forward) para simular a implantação real
Muitas “estratégias milagrosas de backtest” fracassam não pela piora do mercado, mas porque os métodos de teste eram excessivamente otimistas desde o início.
6. Cinco armadilhas comuns de dados
Look-ahead bias
Utilizar dados indisponíveis no momento gera resultados artificialmente elevados.
Survivorship bias
Treinar apenas com moedas ou plataformas sobreviventes — ignorando amostras que falharam.
Limpeza excessiva
Excluir ruído real como se fosse dado sujo — o modelo perde capacidade de adaptação a mercados extremos.
Feature leakage
Features que contêm informações da label — fazendo o modelo parecer mais preciso do que realmente é.
Frequency mismatch
Forçar features on-chain de baixa frequência em tarefas de negociação de alta frequência — gerando sinais falsos.
Essas falhas não aparecem no backtest, mas se amplificam rapidamente na negociação ao vivo.
Um fluxo de trabalho prático: comece pequeno e estável, depois expanda
Para quem está aprendendo, o caminho mais seguro não é iniciar com um “mega-modelo de todos os fatores do mercado”, mas sim com uma estrutura de dados mínima viável:
- Escolha um único ativo (como o BTC ou ETH)
- Comece com dados de mercado e derivativos
- Desenvolva de 10 a 20 features básicas com significado econômico
- Defina uma label clara (ex.: se o retorno futuro em 4 horas >0)
- Valide com séries temporais e teste com janela móvel
- Adicione gradualmente fatores on-chain e de texto
Esse método mantém a identificação dos problemas clara, reduz o custo de iteração e encurta o caminho para implantação.
Sistemas complexos não surgem prontos — crescem camada a camada, a partir de sistemas pequenos e interpretáveis.
O verdadeiro papel do Gate for AI na camada de dados
Na prática, a etapa de dados é geralmente a mais trabalhosa: coleta de múltiplas fontes, limpeza de formatos, alinhamento temporal, pipelines de features e integração de estratégias.
Por isso, ferramentas de IA baseadas em plataformas ganham cada vez mais relevância. O valor do Gate for AI, enquanto infraestrutura, não está em “gerar uma estratégia universal”, mas em apoiar traders na execução eficiente do ciclo de engenharia — dos dados à estratégia — e reduzir o atrito entre pesquisa e execução. Cabe ao trader definir problemas, estabelecer restrições e gerir riscos — mas os fluxos operacionais podem ser padronizados e reutilizáveis.