Traditional blockchains usually treat data as secondary content. Storage and execution are separated, making it difficult for on-chain applications to use large-scale data directly and forcing them to rely on external services. Irys attempts to solve this structural problem by integrating “data storage, verification, and execution” into a single system.
The key to understanding Irys is understanding its full data lifecycle: how data is uploaded, how it is verified across the network, and how it is accessed and used. At the same time, its underlying “partitioned storage and mining mechanism,” known as the Partition Lifecycle, is central to understanding its verifiability.
The Basic Principles of Irys Data Storage: A Decentralized Data Layer and Verifiable Storage Mechanism
Irys uses a “Datachain” structure, bringing data directly into the blockchain consensus system. Unlike traditional storage, data is not simply saved. It becomes a verifiable on-chain state.
In this model, every piece of data must be confirmed by the network as “truly existing and accessible.” This mechanism turns data from something that is “passively stored” into something that can be “proven to exist,” thereby improving the trustworthiness of the system.
In addition, Irys integrates data with the execution environment, allowing data not only to be read, but also to participate in on-chain computation. This design upgrades it from a “storage protocol” into a “data infrastructure layer.”
Data Upload Process: The Write Path from User Submission to On-Chain Record
In Irys, uploading data is similar to submitting a blockchain transaction. The user first packages the data and submits it to the network, after which the data enters the on-chain processing flow.
The data is not stored in one centralized location. Instead, it is split and assigned to different storage partitions across the network. These partitions are the basic units of Irys’s storage structure. Each partition has a capacity of about 16TB, helping the network remain scalable while keeping storage costs manageable.
As data is written into blocks, its state is recorded on-chain and then moves into the subsequent verification process. This forms the complete data write path and provides the foundation for later verification and retrieval.
Source: irys.xyz
Data Verification Mechanism: How Irys Achieves Data Verifiability, Proof of Storage / Availability
Irys’s key innovation is that it incorporates data verification into the consensus mechanism. Each block not only confirms transactions, but must also prove that the data still exists and remains accessible.
This mechanism is implemented through “data sampling + hash verification.” The network continuously requires nodes to read portions of the data and perform computations, thereby confirming that the data is genuinely stored rather than falsely claimed to exist.
Irys also introduces a mechanism similar to “storage mining”: nodes must continuously read and verify data blocks in order to participate in block production. This makes data verification part of the network’s operation, rather than an added feature.
This design addresses a core challenge in decentralized storage: how to confirm that data exists without requiring trust.
Data Retrieval and Queries: How Irys Data Is Accessed, Indexed, and Called
Once data has been stored and verified, users can query and retrieve it through a data identifier. Nodes in the network return the corresponding data content based on the request.
Unlike traditional storage, Irys data is not only readable, but can also be called directly by on-chain applications. This means smart contracts can execute logic based on this data without relying on external APIs.
This “readable + computable” structure gives Irys stronger infrastructure characteristics in Web3 applications, especially for data-driven use cases.
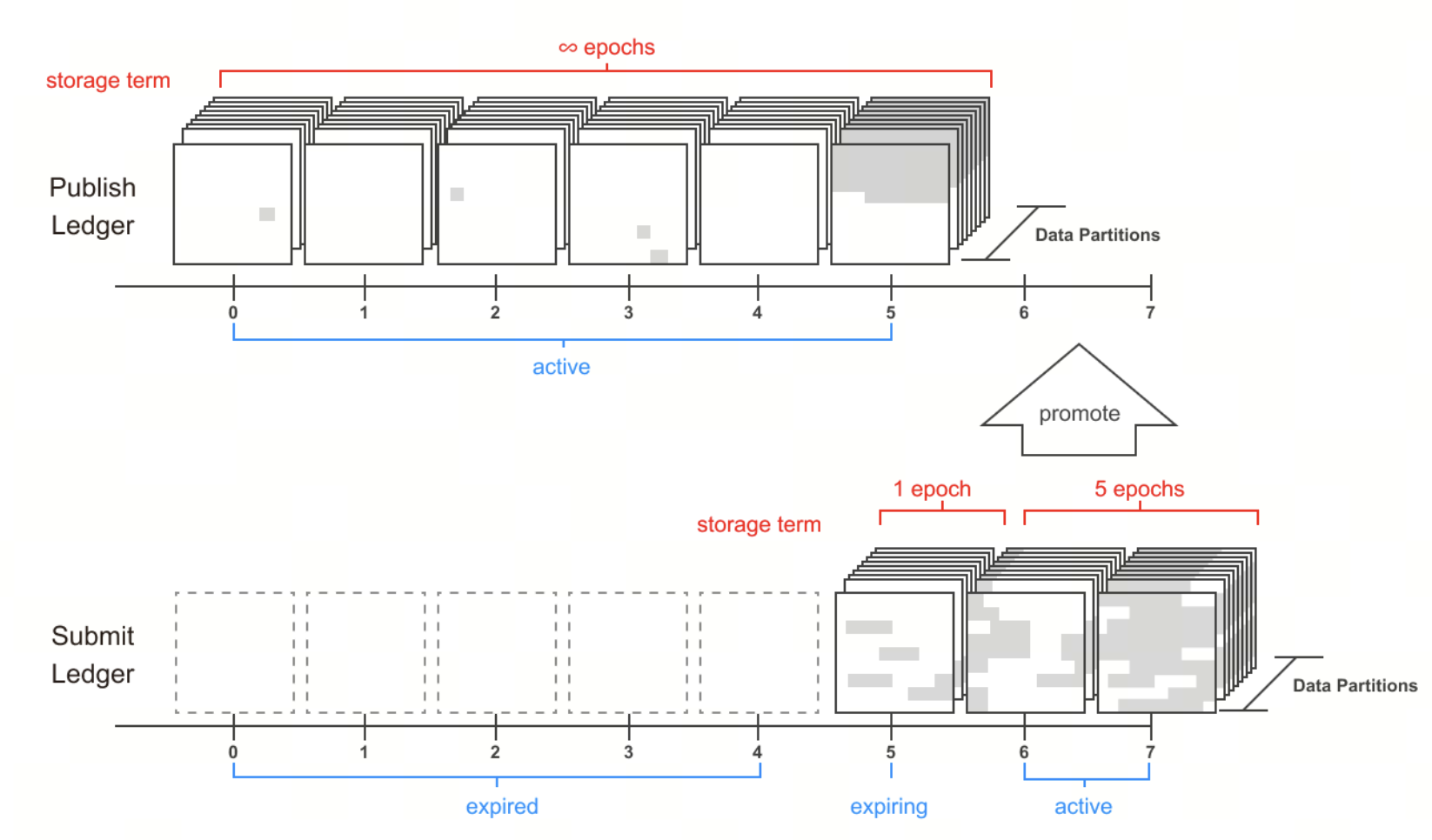
How Data Availability Is Guaranteed: Nodes, Consensus, and the Partition Mechanism
Irys ensures long-term data availability through the “Partition Lifecycle” mechanism.
The network divides storage into multiple 16TB partitions and maintains operation through the following process:
-
Partition Pledging: Nodes stake tokens to apply for participation in storage
-
Partition Packing: Matrix Packing binds data to node identity, preventing replication attacks
-
Partition Mining: Nodes continuously read data and participate in computation to prove that the data exists
-
Ledger Assignment: More efficient nodes are more likely to be assigned real data and receive higher rewards
Throughout this process, nodes must continuously prove their storage capacity. Otherwise, they may lose rewards or even face penalties.
In addition, when a node exits the network, the system automatically reallocates the data to ensure that node downtime does not result in data loss. This mechanism makes data availability an inherent property of the system.
Irys’s greatest strength lies in “verifiable data.” Data no longer depends on trust. Instead, the network continuously proves that it exists, providing a foundation for highly trustworthy applications.
Second, its integrated “data + execution” structure allows applications to directly use on-chain data, reducing reliance on external systems. This is especially important for areas such as DeFi and AI data.
However, its limitations are also fairly clear. The first is high system complexity, involving partitions, verification, and consensus mechanisms. The second is higher resource requirements, including storage and computation costs.
As a result, Irys is better suited for scenarios that require high data trustworthiness, rather than simple file storage needs.
Summary
Irys builds a new kind of Web3 data infrastructure by integrating data storage, verification, and execution into the same system. Its core idea is that data should not only exist, but also be provable and able to participate in computation.
Through its partition mechanism and continuous verification model, Irys ensures long-term data availability and reduces reliance on external systems. This structure distinguishes it from traditional storage protocols and makes it a representative example of a “verifiable data layer.”
FAQ
1.Why Does Irys Data Need to Be Verified?
Because a decentralized network cannot trust a single node, it must use a verification mechanism to confirm that data truly exists.
2.What Is a Partition?
A partition is the storage unit in Irys. Each partition is used to store and verify a certain amount of data.
3.What Is the Role of Matrix Packing?
It is used to bind data to nodes, preventing nodes from cheating by simply copying data.
4.How Does Irys Ensure Data Is Not Lost?
Through distributed storage and partition reallocation mechanisms, Irys can maintain data integrity even when nodes leave the network.
5.What Is the Biggest Difference Between Irys and Traditional Storage?
Traditional storage focuses on “saving data,” while Irys emphasizes that “data can be verified and participate in computation.”