AIトレーディングのデータ基盤—モデルに最適なデータとは?
本レッスンでは「データが戦略の上限を決定する仕組み」を導入として、AI暗号資産トレーディングに必要なデータの種類、特徴量構築手法、よくあるデータの落とし穴を体系的に解説いたします。学習者がライブトレーディングに適したリサーチの出発点を確立できるようサポートします。
はじめに
レッスン1では、AIが暗号資産取引の新たなインフラとなる理由について解説しました。次に重要なのは、どれほどAIが強力であっても、与えられたデータの枠内でしか機能しないという点です。
多くの戦略が失敗する主な理由は、モデルの単純さではなく、データ層での方向性の誤りです。データの質が低い、特徴設計が歪んでいる、検証手法にバイアスがある、などが挙げられます。
したがって、本格的なAI取引は「モデル選び」から始まるのではなく、「データ基盤の構築」から始まります。モデルに与えるデータがモデルの視野を決め、その視野が判断の幅を決めます。
1. まずコンセンサスを確立する:データは多ければ良いわけではなく、因果構造を持つデータが重要
AI初心者のトレーダーは「データをとにかく集める」傾向に陥りやすく、あらゆるデータを集め、特徴量が多いほどAlphaが見つかると考えます。
しかし、質の低いノイズや相関の弱いデータは、むしろモデルの安定性を損ないます。その理由は明快です:
- モデルがノイズから「誤ったパターン」を学習してしまう
- アウトサンプル環境が変化すると誤パターンが真っ先に崩れる
- 特徴量が冗長になるほど戦略の説明や維持管理が難しくなる
つまり、データシステム構築の第一原則は次の通りです:
取引課題を中心にデータを選定し、データ自体から課題を探さないこと。
「短期的な方向予測」を目指す場合はミクロ構造やセンチメントショックを重視し、「中期的なポジション管理」なら流動性やボラティリティ構造、マクロ要因を重視してください。
2. AI暗号資産取引における4つの主要データソース
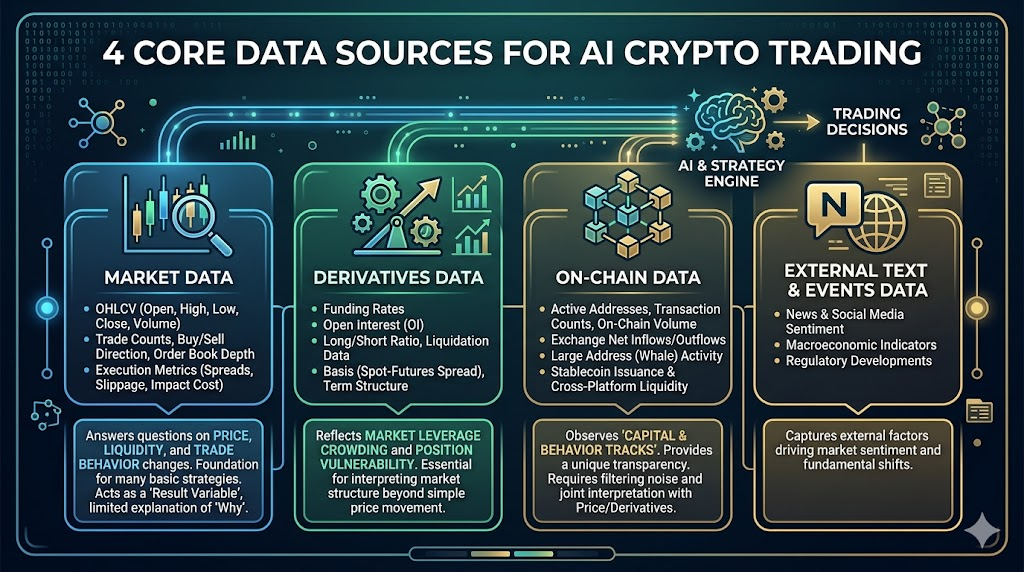
暗号資産市場で最も価値のあるデータは、マーケットデータ・デリバティブ・オンチェーン・外部情報の4層に分類されます。
マーケットデータ
すべての戦略の基盤となる層で、以下が含まれます:
- OHLCV(始値・高値・安値・終値・出来高)
- 取引回数、売買方向、オーダーブックのデプス
- スプレッド、スリッページ、執行コスト指標
価格・流動性・取引行動の変化を把握できます。
マーケットデータだけでも多くの基本戦略は構築できますが、「なぜ変化するか」を説明する力が限定的で、「結果変数」に近いという限界があります。
デリバティブデータ
特に暗号資産市場で重要で、次のようなデータが含まれます:
- 資金調達率
- 建玉
- ロング/ショート口座比率、清算データ
- ベーシス(現物-先物価格差)、期間構造
このデータは、市場のレバレッジ集中やポジションの脆弱性を反映します。
例えば、「価格上昇+建玉増加+高い資金調達率」と「価格上昇+建玉減少」では意味が全く異なります。前者はトレンド強化やレバレッジ集中、後者はショートカバー主導の可能性が高いです。
デリバティブの視点がなければ、市場変動の背後にあるポジション構造を正確に判断することは困難です。
オンチェーンデータ
暗号資産市場が伝統市場と差別化される重要な利点で、以下が含まれます:
- アクティブアドレス数、トランザクション数、オンチェーン送金規模
- 取引所への純流入/流出
- 大口アドレス(クジラ)の行動
- ステーブルコイン発行量やクロスプラットフォームフロー
オンチェーンデータの価値は「資金や行動の軌跡」を観察できる点ですが、解釈の遅延やノイズ除去が課題となります。
例えば、取引所への流入増加は売却準備かヘッジ準備かを示す場合があります。オンチェーンデータは価格構造やデリバティブデータと組み合わせて解釈する必要があり、単独で使うと誤判断につながりやすいです。
外部テキスト・イベントデータ(ニュース/ソーシャル/マクロ)
ニュース、ソーシャルメディアの議論熱、政策イベント、マクロデータ発表タイミングなどが含まれます。
これらは「ショックソースデータ」として、ボラティリティの急上昇やトレンドの一時的な転換の説明に役立ちます。
ただし、この種のデータは主観性が高く、ノイズや真偽混在の情報が多いという課題があります。
そのため、外部テキストは「リスク警告要素」や「イベントフィルター」として活用し、単独のエントリーシグナルとしては推奨されません。
3. 生データから取引可能な特徴量へ:特徴量エンジニアリングこそが戦略の分水嶺
AIは「市場のストーリー」を直接理解するのではなく、特徴量のパターンのみを認識します。
したがって、次の段階はモデル学習を急ぐことではなく、生データを学習可能・検証可能・取引可能な特徴量へと変換することです。
有用な特徴量は主に4つのカテゴリに分類できます:
- トレンド系特徴量:価格変動の勢い、移動平均の傾き、ブレイクアウト強度
- ボラティリティ系特徴量:過去のボラティリティ、レンジ幅、ボラティリティジャンプ
- 構造系特徴量:資金調達率の乖離、建玉変化率、ベーシス変化
- 行動系特徴量:オンチェーン純流動変化、ニュースセンチメントショック、異常なソーシャルメディア熱
本質的に重要なのは「派手な特徴量」ではなく、次の3つの基準です:
- 経済的な意味があるか(単なる数学的な結合でないこと)
- リアルタイムで取得可能か(未来情報を含まないこと)
- 異なる市場局面(強気・弱気・レンジ)でも過度な歪みなく持続可能か
4. ラベル設計:モデルに何を予測させるかが学習内容を決める
多くの人がモデルに「次のK線の上下」を予測させがちですが、それが最適とは限りません。
取引目標に応じて、ラベルの形は様々です:
- 分類ラベル:将来n期間リターンが閾値を超えるか
- 回帰ラベル:将来n期間リターン
- リスクリベル:将来n期間で大きなドローダウンが発生するか
- 構造ラベル:将来ボラティリティ拡大や資金調達率極端化が起きるか
例えば戦略目標が「大きなドローダウン回避」なのに「短期価格方向」をラベルにしてしまうと、どれだけモデル精度が高くても役立ちません。
ラベルは戦略目標と一致させるべきです。取引で得たい利益を、そのままモデルに学習させてください。
5. データ検証の鍵:時系列の世界では検証手法がモデル以上に重要
一般的な機械学習タスクでは、トレーニングセットとテストセットをランダムにシャッフルするのが一般的ですが、取引ではこれが大きな歪みを生みます。
市場は時系列構造を持つため、未来の情報が過去に「漏れる」ことは絶対に避けなければなりません。
AI取引では最低でも次の3つの検証ルールを守ってください:
- トレーニング/検証/テストは時間軸で分割し、ランダムシャッフルしない
- アウトサンプル検証は異なるボラティリティ環境をカバーすること
- ローリングウィンドウ(ウォークフォワード)で実運用を模擬すること
多くの「バックテストで奇跡的な戦略」は、市場環境の悪化よりも検証手法自体の楽観バイアスによって崩壊します。
6. 代表的なデータの落とし穴5つ
ルックアヘッドバイアス
当時入手不可能なデータを使い、結果が過大評価される。
サバイバーシップバイアス
生き残ったコインやプラットフォームだけで学習し、消滅したサンプルを無視する。
過剰クリーニング
本来のノイズを異常値として削除し、モデルが極端な市場への適応力を失う。
特徴量リーケージ
特徴量が暗黙的にラベル情報を含み、モデルが過度に高精度に見える。
頻度ミスマッチ
低頻度オンチェーン特徴量を高頻度取引タスクに無理やり適用し、誤シグナルを生む。
これらの問題はバックテスト中は検知されませんが、ライブトレーディングでは急速に拡大します。
実践的なデータワークフロー:小さく安定して始め、徐々に拡張する
コース学習者にとって最も安全なアプローチは、「全銘柄・全要素の巨大モデル」から始めるのではなく、最小限の実用的なデータフレームワークから始めることです:
- 単一のアセット(BTCやETHなど)を選ぶ
- マーケット+デリバティブデータから始める
- 経済的意味のある基本特徴量を10〜20個構築する
- 明確なラベルを設計する(例:将来4時間リターンが0を超えるか)
- 時系列検証+ローリングテストを行う
- オンチェーンやテキスト要素を徐々に追加する
この方法なら課題の切り分けが明確で、反復コストも低く、導入までの道のりも短くなります。
複雑なシステムは一度に構築されるのではなく、解釈可能な小さなシステムから段階的に拡張されていきます。
Gate for AIのデータ層における本当の意義
実際の運用では、データ段階が最も時間を要する部分となります。マルチソース収集、フォーマットクリーニング、時系列整合、特徴量パイプライン、戦略統合などが必要です。
そのため、プラットフォーム型AIツールの重要性が高まっています。Gate for AIのようなインフラの価値は、「万能な戦略を自動生成する」ことではなく、トレーダーがデータから戦略までのエンジニアリングループを効率的に完了し、リサーチと実行の摩擦を減らすことにあります。トレーダー自身が課題を定義し、制約を設定し、リスクを管理する必要はありますが、基盤となるワークフローはより標準化・再利用可能になります。
関連コース

暗号資産におけるアイデンティティ:主なプロジェクト

マスターノードトークンの紹介

分散型アイデンティティの基礎

暗号デリバティブ:主なプロジェクト

暗号資産における自分自身の調査(DYOR)を行う
