Pendahuluan
Pada Pelajaran 1, kita membahas alasan AI menjadi infrastruktur baru dalam perdagangan kripto. Pertanyaan utama berikutnya adalah: sekuat apa pun AI, AI hanya dapat bekerja dalam batasan data yang Anda berikan.
Banyak strategi gagal bukan karena modelnya terlalu sederhana, melainkan karena terjadi kesalahan arah pada lapisan data: kualitas data yang kurang, desain fitur yang tidak tepat, atau metode validasi yang bias.
Karena itu, perdagangan AI sejati umumnya tidak dimulai dari “memilih model”, melainkan dari “membangun fondasi data”. Data yang Anda masukkan ke model menentukan apa yang dapat dikenali model; apa yang dapat dikenali model menentukan keputusan yang dapat dihasilkannya.
1. Bangun Konsensus Terlebih Dahulu: Lebih Banyak Data Tidak Selalu Lebih Baik—Data dengan Struktur Kausal Lebih Bernilai
Trader yang baru menggunakan AI sering terjebak pola pikir “menimbun data”: mengumpulkan semua data yang tersedia, menganggap semakin banyak fitur akan semakin mudah menemukan alpha.
Faktanya, data berkualitas rendah, bising, dan berkorelasi lemah justru menurunkan stabilitas model. Alasannya sederhana:
- Model belajar pola palsu dari noise
- Saat lingkungan out-of-sample berubah, pola palsu adalah yang pertama gagal
- Semakin banyak fitur yang berlebihan, semakin sulit strategi dijelaskan dan dipelihara
Jadi, prinsip utama membangun sistem data adalah:
Pilih data berdasarkan masalah perdagangan—bukan mencari masalah dari data itu sendiri.
Jika Anda ingin memecahkan “prediksi arah jangka pendek”, prioritaskan mikrostruktur dan guncangan sentimen; jika Anda fokus pada “manajemen posisi jangka menengah”, utamakan likuiditas, struktur volatilitas, dan faktor makro.
2. Empat Sumber Data Utama untuk Perdagangan Kripto AI
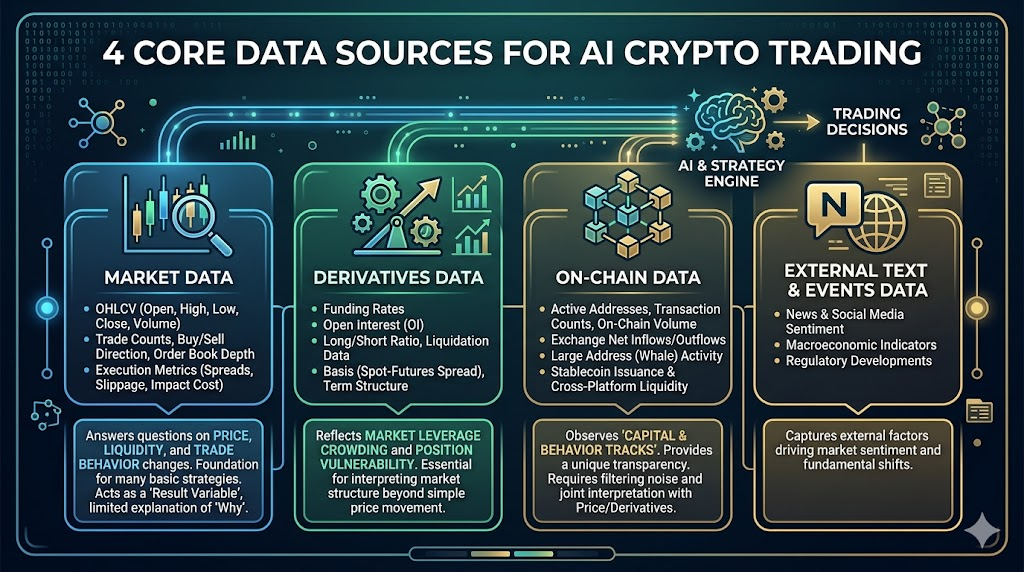
Di pasar kripto, data paling bernilai biasanya berasal dari empat lapisan: data pasar, derivatif, on-chain, dan informasi eksternal.
Data Pasar
Ini adalah lapisan dasar untuk semua strategi, meliputi:
- OHLCV (Open, High, Low, Close, Volume)
- Jumlah perdagangan, arah beli/jual, kedalaman order book
- Spread, slippage, indikator biaya eksekusi
Data ini menjawab: bagaimana harga berubah, bagaimana likuiditas berubah, dan bagaimana perilaku perdagangan berubah.
Banyak strategi dasar dapat dibangun hanya dengan data pasar, namun kekurangannya adalah: data ini lebih sebagai “variabel hasil”, sehingga terbatas untuk menjelaskan “mengapa sesuatu berubah”.
Data Derivatif
Data ini sangat penting di pasar kripto, meliputi:
- Funding rate
- Open interest
- Rasio akun long/short, data likuidasi
- Basis (selisih harga spot-kontrak), struktur tenor
Data ini mencerminkan penumpukan leverage dan kerentanan posisi pasar.
Contohnya, “harga naik + OI naik + funding rate tinggi” dibandingkan “harga naik + OI turun” memiliki makna yang sangat berbeda. Yang pertama bisa menandakan penguatan tren atau penumpukan leverage; yang kedua umumnya didorong oleh short covering.
Tanpa dimensi derivatif, sulit menilai struktur posisi di balik pergerakan pasar.
Data On-chain
Keunggulan utama yang membedakan pasar kripto dari pasar tradisional, meliputi:
- Alamat aktif, jumlah transaksi, ukuran transfer on-chain
- Aliran masuk/keluar bersih ke bursa
- Perilaku alamat besar (whale)
- Penerbitan stablecoin dan arus lintas platform
Nilai data on-chain terletak pada pengamatan “lintasan modal dan perilaku”, namun tantangannya adalah interpretasi yang tertunda dan penyaringan noise.
Misalnya, peningkatan aliran masuk ke bursa bisa berarti persiapan untuk menjual atau melakukan hedge. Data on-chain harus diinterpretasikan bersama dengan struktur harga dan data derivatif—menggunakan data ini secara tunggal sangat mudah menimbulkan kesalahan penilaian.
Data Teks dan Event Eksternal (Berita/Sosial/Makro)
Mencakup berita, intensitas diskusi di media sosial, peristiwa kebijakan, dan waktu rilis data makro.
Jenis data ini lebih sebagai “data sumber guncangan”: menjelaskan mengapa volatilitas tiba-tiba melonjak atau tren berubah sesaat.
Tetapi data jenis ini jelas bermasalah: sangat subjektif, bising, dan bercampur informasi benar/salah.
Oleh karena itu, teks eksternal lebih tepat digunakan sebagai “faktor peringatan risiko” dan “filter event”, bukan sebagai sinyal utama masuk pasar.
3. Dari Data Mentah ke Fitur Siap Perdagangan: Rekayasa Fitur adalah Pembeda Strategi Sesungguhnya
AI tidak memahami “narasi pasar” secara langsung; AI hanya mengenali pola fitur.
Jadi, langkah kedua bukan terburu-buru melatih model, melainkan mengubah data mentah menjadi fitur yang bisa dipelajari, diverifikasi, dan diperdagangkan.
Fitur umum yang berguna dapat dikelompokkan menjadi empat kategori:
- Fitur Tren: momentum, kemiringan moving average, kekuatan breakout
- Fitur Volatilitas: volatilitas historis, amplitudo kisaran, lonjakan volatilitas
- Fitur Struktural: deviasi funding rate, laju perubahan OI, perubahan basis
- Fitur Perilaku: perubahan aliran bersih on-chain, guncangan sentimen berita, lonjakan abnormal diskusi media sosial
Kuncinya bukan “fitur yang mencolok”, melainkan tiga standar utama:
- Apakah fitur tersebut bermakna secara ekonomi (bukan sekadar hitungan matematis)
- Apakah dapat diperoleh secara real-time (tanpa informasi masa depan)
- Apakah fitur tersebut bertahan di berbagai fase pasar (bull/bear/konsolidasi tanpa distorsi berlebihan)
4. Desain Label: Apa yang Anda Minta Model Prediksi Menentukan Apa yang Dipelajarinya
Banyak orang secara default meminta model memprediksi “K-line berikutnya naik/turun”, namun ini belum tentu optimal.
Tujuan perdagangan dapat memiliki berbagai bentuk label:
- Label klasifikasi: apakah return n-periode ke depan melebihi ambang batas
- Label regresi: return n-periode ke depan
- Label risiko: apakah terjadi drawdown besar di n periode ke depan
- Label struktural: apakah volatilitas meluas atau funding rate menjadi ekstrem di masa depan
Jika tujuan strategi Anda adalah “menghindari drawdown besar” namun Anda menggunakan “arah harga jangka pendek” sebagai label, seakurat apa pun modelnya, hasilnya belum tentu bermanfaat.
Jadi, label harus selaras dengan tujuan strategi: keuntungan apa pun yang Anda incar dalam perdagangan, latih model untuk mempelajari target tersebut.
5. Kunci Validasi Data: Dalam Dunia Time Series, Metode Validasi Lebih Penting daripada Model
Pada tugas machine learning umumnya, mengacak set pelatihan dan pengujian secara acak adalah hal yang lumrah dan masuk akal; namun dalam perdagangan, hal ini menyebabkan distorsi besar.
Sebab pasar memiliki struktur ketergantungan waktu—informasi masa depan tidak boleh bocor ke masa lalu.
Perdagangan AI setidaknya harus mematuhi tiga aturan validasi berikut:
- Pisahkan pelatihan/validasi/pengujian berdasarkan waktu—bukan acak
- Validasi out-of-sample harus mencakup lingkungan volatilitas yang berbeda
- Gunakan rolling window (walk-forward) untuk simulasi deployment nyata
Banyak “strategi ajaib backtest” gagal bukan karena pasar memburuk, melainkan karena metode pengujian sudah bias secara optimistis sejak awal.
6. Lima Kesalahan Data yang Umum Terjadi
Look-ahead Bias
Menggunakan data yang belum tersedia pada saat itu menyebabkan hasil yang berlebihan.
Survivorship Bias
Melatih hanya pada koin atau platform yang bertahan—mengabaikan sampel yang gagal.
Over-cleaning
Menghapus noise nyata sebagai data kotor—model kehilangan kemampuan adaptasi terhadap pasar ekstrem.
Feature Leakage
Fitur secara implisit mengandung informasi label—membuat model terlihat terlalu akurat.
Frequency Mismatch
Memaksakan fitur on-chain frekuensi rendah ke tugas perdagangan frekuensi tinggi—menyebabkan sinyal palsu.
Masalah-masalah ini tidak terlihat saat backtesting, namun akan cepat membesar dalam perdagangan live.
Alur Kerja Data Praktis: Mulai dari yang Kecil dan Stabil, Lalu Berkembang
Bagi pelajar kursus, pendekatan paling aman bukan memulai dengan “mega-model semua faktor seluruh pasar”, melainkan mulai dari kerangka data minimum yang layak:
- Pilih satu aset (misal BTC atau ETH)
- Mulai dari data pasar + derivatif
- Bangun 10–20 fitur dasar yang bermakna secara ekonomi
- Rancang label yang jelas (misal, apakah return 4 jam ke depan >0)
- Validasi time series + pengujian rolling
- Secara bertahap tambahkan faktor on-chain dan teks
Pendekatan ini menjaga pelokalan masalah tetap jelas, biaya iterasi rendah, dan jalur deployment singkat.
Sistem kompleks tidak dibangun sekaligus—tetapi berkembang lapis demi lapis dari sistem kecil yang dapat dijelaskan.
Makna Nyata Gate for AI di Lapisan Data
Dalam implementasi nyata, tahap data sering kali menjadi bagian paling memakan waktu: pengumpulan dari berbagai sumber, pembersihan format, penyelarasan waktu, pipeline fitur, dan integrasi strategi.
Itulah mengapa alat AI berbasis platform semakin penting. Gate for AI sebagai contoh infrastruktur semacam ini—nilainya bukan pada “menghasilkan strategi universal”, melainkan membantu trader menyelesaikan siklus engineering dari data ke strategi secara efisien dan mengurangi friksi antara penelitian dan eksekusi. Trader tetap perlu mendefinisikan masalah, menetapkan batasan, dan mengelola risiko—namun alur kerja dasarnya bisa lebih terstandarisasi dan dapat digunakan ulang.





