Introduction
Dans la Leçon 1, nous avons expliqué pourquoi l’IA s’impose comme la nouvelle infrastructure du trading crypto. La question essentielle qui en découle est la suivante : quelle que soit sa puissance, l’IA ne peut fonctionner que dans les limites des données que vous lui fournissez.
De nombreuses stratégies échouent non pas à cause de la simplicité du modèle, mais en raison d’erreurs d’orientation au niveau des données : qualité insuffisante, conception des features déformée ou méthodes de validation biaisées.
En conséquence, le trading crypto basé sur l’IA ne commence pas par le « choix du modèle », mais par la « construction de la base de données ». Ce que vous fournissez au modèle détermine ce qu’il peut percevoir ; ce qu’il perçoit conditionne la pertinence de ses jugements.
1. Établir d’abord un consensus : plus de données n’est pas toujours mieux — privilégier les données à structure causale
Les traders débutants en IA adoptent souvent une logique de « thésaurisation des données » : accumuler toutes les données disponibles, pensant que plus de features facilitent la recherche d’alpha.
En réalité, les données de faible qualité, bruitées ou faiblement corrélées réduisent la stabilité du modèle. La raison est simple :
- Le modèle « apprend de faux schémas » issus du bruit
- Lorsque les conditions de marché changent, ces schémas sont les premiers à échouer
- Plus les features sont redondantes, plus la stratégie devient complexe à expliquer et à maintenir
Le premier principe pour bâtir un système de données est donc :
Sélectionner les données en fonction des problématiques de trading — et non chercher des problèmes à partir des données elles-mêmes.
Si l’objectif est de « prédire la direction à court terme », privilégiez la microstructure et les chocs de sentiment ; pour la « gestion de position à moyen terme », concentrez-vous sur la liquidité, la structure de la volatilité et les facteurs macroéconomiques.
2. Quatre sources de données clés pour le trading crypto avec IA
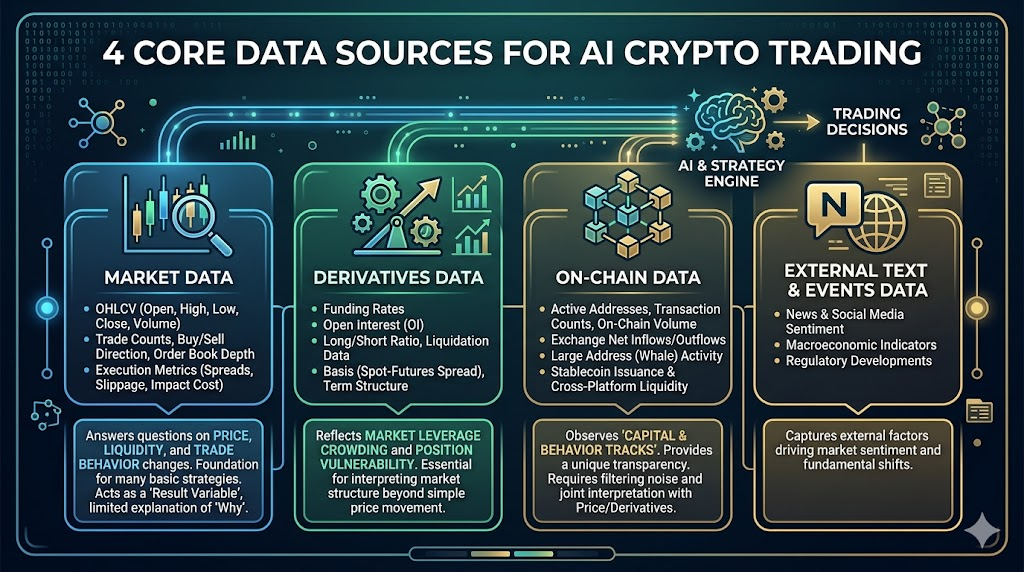
Sur les marchés crypto, les données les plus précieuses proviennent généralement de quatre niveaux : données de marché, produits dérivés, on-chain et informations externes.
Market Data
Il s’agit de la base de toutes les stratégies, comprenant :
- OHLCV (Open, High, Low, Close, Volume)
- Nombre de trades, sens achat/vente, profondeur du carnet d’ordres
- Spread, slippage, indicateurs de coût d’exécution
Elle permet de comprendre : l’évolution des prix, l’évolution de la liquidité, l’évolution des comportements de trading.
De nombreuses stratégies fondamentales peuvent être construites uniquement à partir de données de marché, mais leur limite est claire : elles sont plutôt une « variable de résultat », avec un pouvoir explicatif limité sur les causes des évolutions.
Derivatives Data
Essentielles sur les marchés crypto, elles incluent :
- Taux de financement
- Intérêt ouvert
- Ratio comptes long/short, données de liquidation
- Base (écart spot-contrat), structure des échéances
Ces données reflètent la concentration de l’effet de levier sur le marché et la vulnérabilité des positions.
Par exemple, « prix en hausse + OI en hausse + taux de financement élevé » et « prix en hausse + OI en baisse » révèlent des dynamiques très différentes. Le premier cas peut signaler un renforcement de tendance ou un excès d’effet de levier ; le second est généralement lié à des rachats de positions short.
Sans la dimension des produits dérivés, il est difficile d’analyser la structure des positions derrière les mouvements de marché.
On-chain Data
Un avantage clé qui distingue les marchés crypto des marchés traditionnels, incluant :
- Adresses actives, nombre de transactions, taille des transferts on-chain
- Flux net d’entrée/sortie vers les exchanges
- Comportement des grandes adresses (whales)
- Émission de stablecoins et flux inter-plateformes
La valeur des données on-chain réside dans l’observation des « trajectoires de capitaux et de comportements », mais leur interprétation est complexe et le filtrage du bruit essentiel.
Par exemple, une hausse des flux entrants sur les exchanges peut signifier une préparation à la vente ou à la couverture. Les données on-chain doivent être analysées en lien avec la structure des prix et les données de produits dérivés — les exploiter seules expose à des erreurs de jugement.
Données textuelles et événementielles externes (Actualités/Social/Macro)
Incluent les actualités, l’intensité des discussions sur les réseaux sociaux, les événements politiques, les dates de publication des données macroéconomiques.
Il s’agit de « données sources de chocs » : elles expliquent les pics soudains de volatilité ou les changements de tendance brefs.
Ce type de données présente cependant des limites évidentes : elles sont très subjectives, bruitées et mêlent informations vraies et fausses.
Ainsi, les textes externes sont plus adaptés comme « facteurs d’alerte risque » et « filtres d’événements » que comme signaux d’entrée principaux.
3. Des données brutes aux features exploitables : le feature engineering, véritable frontière stratégique
L’IA ne comprend pas les « narratifs de marché » ; elle détecte uniquement des schémas de features.
La seconde étape consiste donc à transformer les données brutes en features apprenables, vérifiables et exploitables.
Les meilleures features se répartissent en quatre catégories :
- Features de tendance : momentum, pente de la moyenne mobile, force du breakout
- Features de volatilité : volatilité historique, amplitude de l’intervalle, sauts de volatilité
- Features structurelles : écart du taux de financement, taux de variation de l’OI, variation de la base
- Features comportementales : variations nettes des flux on-chain, chocs de sentiment dans les actualités, intensité anormale sur les réseaux sociaux
L’essentiel n’est pas la quantité ou l’originalité des features, mais leur conformité à trois critères :
- Ont-elles une signification économique (et pas seulement mathématique)
- Sont-elles disponibles en temps réel (pas d’informations futures)
- Peuvent-elles persister sur tous les cycles de marché (bull, bear, consolidation) sans distorsion excessive
4. Conception des labels : ce que vous demandez au modèle de prédire conditionne ce qu’il apprend
Beaucoup font par défaut prédire au modèle « la prochaine bougie K à la hausse ou à la baisse », mais ce n’est pas toujours optimal.
Les objectifs de trading peuvent se décliner en plusieurs types de labels :
- Labels de classification : les rendements futurs sur n périodes dépassent-ils un seuil
- Labels de régression : rendements futurs sur n périodes
- Labels de risque : une forte baisse survient-elle sur n périodes à venir
- Labels structurels : volatilité accrue ou taux de financement extrême à venir
Si votre objectif est « d’éviter les fortes baisses » mais que vous utilisez « direction du prix à court terme » comme label, même un modèle très précis sera peu utile.
Les labels doivent donc correspondre aux objectifs de stratégie : tout profit visé doit être intégré à l’apprentissage du modèle.
5. Clé de la validation des données : dans l’univers des séries temporelles, la méthode de validation prime sur le modèle
Dans le machine learning classique, mélanger aléatoirement les ensembles d’entraînement et de test est courant ; en trading, cela induit une forte distorsion.
Les marchés sont structurés par le temps — il ne faut jamais permettre à l’information future de contaminer le passé.
Le trading IA doit respecter trois règles fondamentales de validation :
- Séparer entraînement, validation et test selon la chronologie — jamais de mélange aléatoire
- La validation hors échantillon doit couvrir différents régimes de volatilité
- Utiliser une fenêtre glissante (walk-forward) pour simuler le déploiement réel
Beaucoup de « stratégies miracles en backtest » échouent non à cause du marché, mais à cause de méthodes de test trop optimistes dès le départ.
6. Cinq pièges de données fréquents
Look-ahead Bias
Utiliser des données indisponibles au moment de la décision gonfle artificiellement les résultats.
Survivorship Bias
S’entraîner uniquement sur les actifs ou plateformes ayant survécu, en ignorant les échantillons disparus.
Over-cleaning
Supprimer le bruit réel en le considérant comme une donnée sale — le modèle perd en adaptabilité lors de marchés extrêmes.
Feature Leakage
Les features contiennent implicitement l’information du label, ce qui donne l’illusion d’une précision excessive.
Frequency Mismatch
Forcer l’intégration de features on-chain à faible fréquence dans des tâches de trading à haute fréquence génère de faux signaux.
Ces biais ne sont pas détectés lors du backtest mais s’amplifient rapidement en trading réel.
Un workflow de données pragmatique : commencer petit et stable, puis élargir
Pour les apprenants, la démarche la plus sûre n’est pas de viser d’emblée un « méga-modèle tous facteurs sur tout le marché », mais de commencer avec un framework de données minimal viable :
- Choisir un seul actif (par exemple BTC ou ETH)
- Démarrer avec les données Market et Derivatives
- Construire 10 à 20 features de base à signification économique
- Définir un label clair (ex. : rendement futur sur 4 heures > 0)
- Validation en série temporelle et test glissant
- Ajouter progressivement les facteurs on-chain et textuels
Cette méthode permet de localiser clairement les problèmes, de limiter les coûts d’itération et de raccourcir la mise en production.
Les systèmes complexes ne s’élaborent pas en une seule étape — ils s’étendent couche par couche à partir de systèmes interprétables et robustes.
La véritable valeur de Gate for AI au niveau des données
En pratique, la phase de gestion des données est souvent la plus longue : collecte multi-sources, nettoyage, alignement temporel, pipelines de features, intégration des stratégies.
C’est pourquoi les outils IA sur plateforme prennent une importance croissante. Gate for AI, en tant qu’infrastructure de ce type, n’a pas vocation à « générer une stratégie universelle », mais à accompagner les traders dans la boucle d’ingénierie, de la donnée à la stratégie, et à réduire la friction entre recherche et exécution. Les traders doivent toujours définir leurs problématiques, contraintes et gestion des risques, mais les workflows sous-jacents peuvent être standardisés et réutilisables.





