Introducción
En la Lección 1, vimos por qué la IA se está consolidando como la nueva infraestructura para el trading cripto. La cuestión clave es: por muy potente que sea la IA, solo puede operar dentro de los límites de los datos que le proporciones.
Muchas estrategias fracasan no porque el modelo sea demasiado simple, sino por errores direccionales en la capa de datos: ya sea por insuficiencia en la calidad de los datos, distorsión en el diseño de las características o sesgo en los métodos de validación.
Por eso, el trading con IA en la práctica no parte de “elegir un modelo”, sino de “construir la base de datos”. Lo que alimentas al modelo determina lo que puede percibir; lo que puede percibir condiciona los juicios que puede tomar.
1. Establece primero un consenso: más datos no siempre es mejor; los datos con estructura causal son mejores
Los traders que se inician en IA suelen caer en la mentalidad de “acumulación de datos”: recopilar todo lo posible, creyendo que más características facilitan encontrar alpha.
En realidad, los datos de baja calidad, ruidosos y poco correlacionados reducen la estabilidad del modelo. La razón es clara:
- El modelo “aprende patrones falsos” a partir del ruido
- Cuando el entorno fuera de muestra cambia, estos patrones falsos son los primeros en fallar
- Cuantas más características redundantes, más difícil resulta explicar y mantener la estrategia
Por tanto, el primer principio para construir un sistema de datos es:
Selecciona datos en torno a los problemas de trading, no busques problemas en los propios datos.
Si tu objetivo es la “predicción de dirección a corto plazo”, prioriza la microestructura y los shocks de sentimiento; si trabajas en la “gestión de posiciones a medio plazo”, enfócate en liquidez, estructura de volatilidad y factores macro.
2. Cuatro fuentes de datos clave para el trading cripto con IA
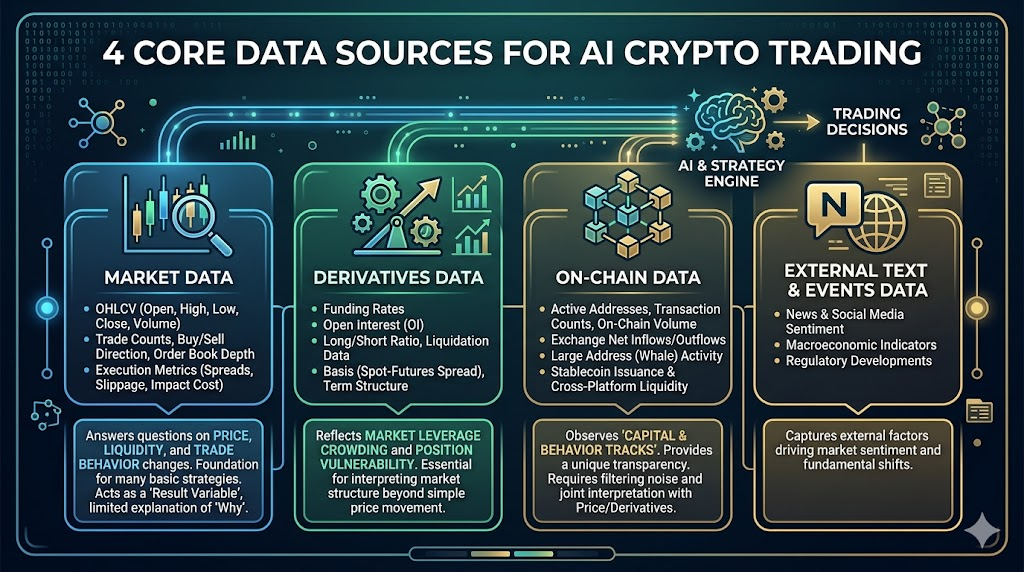
En los mercados cripto, los datos más valiosos suelen proceder de cuatro capas: datos de mercado, derivados, on-chain e información externa.
Datos de mercado
Esta es la base de todas las estrategias, incluyendo:
- OHLCV (open, high, low, close, volumen)
- Número de operaciones, dirección de compra/venta, profundidad del libro de órdenes
- Diferencial, deslizamiento, indicadores de coste de ejecución
Responde a: cómo varían los precios, cómo evoluciona la liquidez y cómo cambia el comportamiento de trading.
Muchas estrategias básicas pueden construirse solo con datos de mercado, pero su limitación es que actúan como “variable de resultado”, con poco poder explicativo sobre “por qué cambian las cosas”.
Datos de derivados
Especialmente relevantes en los mercados cripto, incluyendo:
- Tasa de financiación
- Interés abierto
- Ratio de cuentas largo/corto, datos de liquidación
- Base (diferencial spot-contrato), estructura temporal
Estos datos reflejan la concentración de apalancamiento y la vulnerabilidad de las posiciones en el mercado.
Por ejemplo, “subida de precio + aumento de OI + tasa de financiación alta” frente a “subida de precio + caída de OI” representan escenarios completamente distintos. El primero puede indicar fortalecimiento de la tendencia o concentración de apalancamiento; el segundo suele deberse a cierre de posiciones cortas.
Sin la dimensión de derivados, resulta difícil interpretar la estructura de posiciones tras los movimientos del mercado.
Datos on-chain
Una ventaja clave que diferencia los mercados cripto de los tradicionales, incluyendo:
- Direcciones activas, número de transacciones, tamaño de transferencias on-chain
- Flujo neto de entrada/salida en exchanges
- Comportamiento de grandes direcciones (ballenas)
- Emisión de stablecoin y flujos entre plataformas
El valor de los datos on-chain está en observar “trayectorias de capital y comportamiento”, aunque el reto es la interpretación retardada y el filtrado del ruido.
Por ejemplo, un aumento de entradas a exchanges puede significar intención de venta o de cobertura. Los datos on-chain deben interpretarse junto con la estructura de precios y los datos de derivados; usarlos de forma aislada puede llevar a errores de juicio.
Datos de texto y eventos externos (noticias/social/macro)
Incluye noticias, nivel de discusión en redes sociales, eventos regulatorios y fechas de publicación de datos macroeconómicos.
Este tipo de datos actúa como “fuente de shocks”: explica por qué la volatilidad se dispara o las tendencias cambian de forma repentina.
Sin embargo, presentan problemas evidentes: son subjetivos, ruidosos y mezclan información verdadera y falsa.
Por eso, el texto externo es más adecuado como “factor de alerta de riesgo” y “filtro de eventos”, no como señal de entrada principal.
3. De datos en bruto a características operables: el feature engineering es el verdadero diferenciador estratégico
La IA no comprende directamente las “narrativas de mercado”; solo reconoce patrones en las características.
Por eso, el segundo paso no es entrenar modelos apresuradamente, sino transformar los datos en bruto en características aprendibles, verificables y operables.
Las características útiles habituales se agrupan en cuatro categorías:
- Características de tendencia: impulso, pendiente de la media móvil, fuerza del breakout
- Características de volatilidad: volatilidad histórica, amplitud del rango, saltos de volatilidad
- Características estructurales: desviación de la tasa de financiación, tasa de cambio del OI, variación de la base
- Características de comportamiento: cambios en el flujo neto on-chain, shocks de sentimiento en noticias, actividad social anómala
La clave no reside en “características llamativas”, sino en tres criterios:
- ¿Tiene significado económico (no solo combinación matemática)?
- ¿Se puede obtener en tiempo real (sin información futura)?
- ¿Puede permanecer en diferentes fases de mercado (alcista/bajista/lateral) sin distorsión excesiva?
4. Diseño de etiquetas: lo que pides al modelo que prediga condiciona lo que aprende
Mucha gente configura el modelo para predecir “la subida o bajada de la siguiente vela”, pero esto no siempre es lo óptimo.
Los objetivos de trading pueden adoptar distintas formas de etiquetas:
- Etiquetas de clasificación: si la rentabilidad futura en n periodos supera un umbral
- Etiquetas de regresión: rentabilidad futura en n periodos
- Etiquetas de riesgo: si ocurre una caída relevante en los próximos n periodos
- Etiquetas estructurales: si la volatilidad se expande o la tasa de financiación se vuelve extrema en el futuro
Si tu objetivo es “evitar grandes caídas” pero usas “dirección de precio a corto plazo” como etiqueta, por muy preciso que sea el modelo, puede no servirte de nada.
Por tanto, las etiquetas deben alinearse con los objetivos de la estrategia: aquello que busques como ganancia en el trading, haz que el modelo aprenda ese objetivo.
5. La clave para la validación de datos: en series temporales, el método de validación es más relevante que el propio modelo
En machine learning tradicional, es habitual mezclar aleatoriamente los conjuntos de entrenamiento y prueba; en trading, esto genera distorsiones graves.
Los mercados presentan estructura dependiente del tiempo; la información futura nunca debe “contaminar” el pasado.
El trading con IA debe cumplir al menos tres reglas de validación:
- Separar entrenamiento, validación y prueba por periodos temporales—no mezclar aleatoriamente
- La validación fuera de muestra debe cubrir diferentes entornos de volatilidad
- Usar ventana móvil (walk-forward) para simular el despliegue real
Muchas “estrategias milagro en backtest” colapsan no porque el mercado empeore, sino porque el método de prueba era excesivamente optimista desde el inicio.
6. Cinco errores comunes con los datos
Look-ahead bias
Utilizar datos no disponibles en el momento genera resultados inflados.
Survivorship bias
Entrenar solo con monedas o plataformas que han sobrevivido—ignorando muestras que han fallado.
Sobrelimpieza
Eliminar ruido real como si fuera dato erróneo—el modelo pierde capacidad de adaptación a mercados extremos.
Feature leakage
Las características contienen implícitamente información de la etiqueta—el modelo parece excesivamente preciso.
Desajuste de frecuencia
Forzar características on-chain de baja frecuencia en tareas de trading de alta frecuencia produce señales falsas.
Estos problemas no generan alertas durante el backtesting, pero se amplifican rápidamente en el trading real.
Un flujo de trabajo de datos práctico: empieza pequeño y estable, luego expande
Para los estudiantes del curso, el enfoque más seguro no es partir de un “mega-modelo con todos los factores del mercado”, sino empezar con un marco de datos mínimo viable:
- Selecciona un solo activo (como BTC o ETH)
- Empieza con datos de mercado y derivados
- Construye entre 10 y 20 características básicas con significado económico
- Diseña una etiqueta clara (por ejemplo, si la rentabilidad futura en 4 h es >0)
- Valida con series temporales y test con ventana móvil
- Incorpora gradualmente factores on-chain y de texto
Este enfoque permite localizar los problemas con claridad, mantener bajos los costes de iteración y acortar el camino hacia el despliegue.
Los sistemas complejos no se construyen de golpe; se expanden capa a capa a partir de sistemas pequeños e interpretables.
El verdadero valor de Gate for AI en la capa de datos
En la práctica, la fase de datos suele ser la más laboriosa: recopilación de múltiples fuentes, limpieza de formatos, alineación temporal, desarrollo de pipelines de características e integración de estrategias.
Por eso, las herramientas de IA basadas en plataforma son cada vez más relevantes. Tomando Gate for AI como ejemplo de esta infraestructura, el valor no reside en “generar una estrategia universal para ti”, sino en ayudar a los traders a completar de forma eficiente el ciclo de ingeniería de datos a estrategia y reducir la fricción entre investigación y ejecución. Los traders siguen definiendo problemas, estableciendo restricciones y gestionando riesgos, pero los flujos de trabajo subyacentes pueden ser más estandarizados y reutilizables.






