AI 交易的數據基礎——模型需要輸入哪些數據?
本課程以「數據如何決定策略上限」為主題,系統性說明 AI 加密貨幣交易所需的數據類型、特徵建構方式,以及常見數據誤區,協助學員建立適合實盤交易的研究主幹。
引言
在第 1 課,您已經掌握 AI 為何正逐漸成為加密貨幣交易的新型基礎設施。接下來的核心議題在於:無論 AI 再強大,都只能於您所提供的數據邊界內運作。
許多策略失敗,原因並非模型過於簡單,而是數據層出現方向性錯誤,例如數據品質不足、特徵設計失真或驗證方法有偏差。
因此,真正的 AI 交易通常不是從「挑模型」開始,而是從「建構數據基礎」著手。您輸入給模型的數據決定模型能看到什麼,而模型能看到什麼又決定它能做出哪些判斷。
1. 先建立共識:數據不是越多越好,有因果結構的數據更優
許多剛接觸 AI 的交易員容易陷入「數據囤積」心態:盡可能收集所有數據,認為特徵越多越容易找到 Alpha。
事實上,低品質、高噪聲、弱相關的數據反而會降低模型穩定性。原因很簡單:
- 模型容易從噪聲中「學到錯誤模式」
- 樣本外環境變化時,錯誤模式最先失效
- 特徵越冗餘,策略越難解釋與維護
因此,建構數據體系的首要原則是:
應圍繞交易問題選擇數據,而非圍繞數據本身去尋找問題。
若您要解決「短線方向預測」,應優先關注微觀結構與情緒衝擊;若目標是「中線倉位管理」,則更應考慮流動性、波動結構及宏觀因素。
2. AI 加密貨幣交易的四大核心數據源
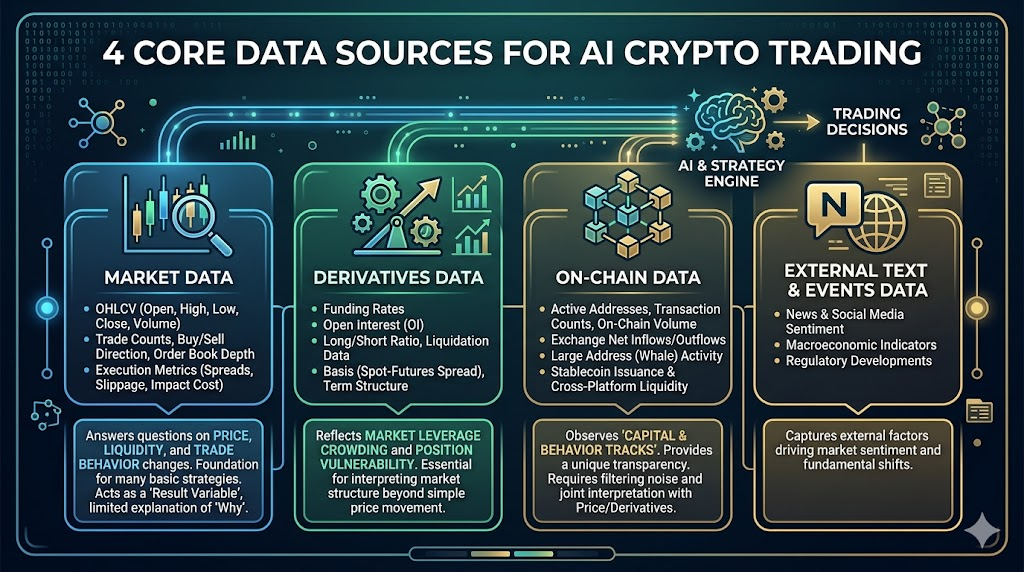
在加密貨幣市場,最具價值的數據通常來自四個層面:市場數據、衍生品數據、鏈上數據與外部資訊。
市場數據
這是所有策略的基礎,包括:
- OHLCV(開盤、高點、低點、收盤、成交量)
- 成交筆數、多空方向、盤口深度
- 點差、滑點、執行成本等指標
它回答了:價格如何變化、流動性如何變化、交易行為如何變化。
許多基礎策略僅憑市場數據即可建構,但其侷限在於:它更像「結果變數」,對「為何變化」的解釋力有限。
衍生品數據
在加密貨幣市場中特別關鍵,包括:
- 資金費率
- 持倉量
- 多空帳戶比例、強制平倉數據
- 基差(現貨-合約價差)、期限結構
這些數據反映市場槓桿擁擠與倉位脆弱性。
例如,「價格上漲 + 持倉量上升 + 資金費率高」與「價格上漲 + 持倉量下降」意義完全不同。前者可能代表趨勢增強或槓桿擁擠,後者則更可能是空頭回補驅動。
若缺乏衍生品維度,很難判斷市場波動背後的倉位結構。
鏈上數據
這是加密貨幣市場區別於傳統市場的核心優勢,包括:
- 活躍地址數、鏈上交易筆數、轉帳規模
- 交易所淨流入/淨流出
- 大戶(巨鯨)地址行為
- 穩定幣發行及跨平台流動
鏈上數據的價值在於觀察「資金與行為軌跡」,但難點在於解釋延遲與噪聲過濾。
例如,交易所流入增加,既可能是準備賣出,也可能是準備對沖。鏈上數據必須結合價格結構與衍生品數據共同解讀,單獨使用容易導致誤判。
外部文本與事件數據(新聞/社交/宏觀)
包括新聞、社交媒體討論熱度、政策事件、宏觀數據發布時間等。
這些更像「衝擊源數據」:用於解釋為何波動突然加劇或趨勢短暫反轉。
但此類數據主觀性強、噪聲大、真假資訊混雜。
因此,外部文本更適合作為「風險預警因子」與「事件篩選器」,不建議作為唯一進場信號。
3. 從原始數據到可交易特徵:特徵工程才是真正的策略分水嶺
AI 並不直接理解「市場敘事」,它只識別特徵模式。
因此第二步不是急於訓練模型,而是要將原始數據轉化為可學習、可驗證、可交易的特徵。
常見有用特徵可分為四類:
- 趨勢特徵:動量、均線斜率、突破強度
- 波動特徵:歷史波動率、區間振幅、波動跳變
- 結構特徵:資金費率偏離、持倉量變化率、基差變化
- 行為特徵:鏈上淨流變化、新聞情緒衝擊、社交媒體異常熱度
關鍵不在於「炫技特徵」,而在於三項標準:
- 是否具經濟意義(而非純數學拼接)
- 能否於實時點取得(不含未來資訊)
- 能否跨牛市、熊市、盤整等不同市況持續有效(不過度失真)
4. 標籤設計:您讓模型預測什麼,它就學到什麼
許多人預設讓模型預測「下一根 K 線漲跌」,但這未必是最優方案。
交易目標可有多種標籤設計:
- 分類標籤:未來 n 週期效益是否超過門檻
- 回歸標籤:未來 n 週期效益
- 風險標籤:未來 n 週期是否發生大回撤
- 結構標籤:未來波動是否擴散或資金費率極端化
若您的策略目標是「規避大回撤」,卻用「短線價格方向」做標籤,不論模型多精準,實際效果可能都不理想。
因此,標籤設計必須與策略目標一致:您在交易中追求哪類效益,就讓模型學習那個目標。
5. 數據驗證關鍵:時序世界中,驗證方法比模型更重要
在一般機器學習任務中,訓練集與測試集隨機打亂是合理的,但在交易領域,這會導致嚴重失真。
因市場具時間依賴結構——未來資訊絕不能「洩漏」到歷史數據。
AI 交易至少應遵循三條驗證原則:
- 按時間切分訓練/驗證/測試集——不能隨機打亂
- 樣本外驗證需涵蓋不同波動環境
- 採用滾動窗口(步進)模擬真實部署
許多「回測奇蹟策略」崩潰,並非市場變壞,而是測試方法本身一開始就過於樂觀。
6. 五大常見數據陷阱
前視偏差
使用當時不可取得的數據,導致結果虛高。
幸存者偏差
只用存活幣種或平台訓練,忽略失敗樣本。
過度清洗
將真實噪聲當髒數據刪除,模型失去對極端行情的適應性。
特徵洩漏
特徵隱含標籤資訊,導致模型表現被高估。
頻率錯配
強行用低頻鏈上特徵做高頻交易,導致假訊號。
這些問題在回測時不會暴露,但在實盤交易中會迅速放大。
實用數據工作流:先小而穩,再擴展
對於課程學員來說,最安全的做法不是一開始就做「全市場全因子大模型」,而是從最小可用數據框架起步:
- 選擇單一資產(如 BTC 或 ETH)
- 從市場 + 衍生品數據類型入手
- 建構 10~20 個具經濟意義的基礎特徵
- 設計清晰標籤(如未來 4 小時效益 >0)
- 時序驗證 + 滾動測試
- 逐步疊加鏈上及文本因子
如此可讓問題定位明確、迭代成本低、上線路徑短。
複雜系統不是一蹴而就,而是從可解釋的小系統逐步擴展。
Gate for AI 在數據層的真正意義
在實際落地過程中,數據環節往往是最耗時的部分:多源採集、格式清洗、時間對齊、特徵管道、策略整合。
因此,平台化 AI 工具愈發重要。以 Gate for AI 這類基礎設施為例,其價值不在於「為您生成萬能策略」,而在於協助交易員高效完成從數據到策略的工程閉環,降低研究與實盤之間的摩擦。交易員仍需定義問題、設定約束、管理風險,但底層流程可更標準化且可重複利用。
相關課程

加密貨幣領域的身份驗證項目概覽

主要加密貨幣衍生品項目概覽

主節點代幣

去中心化身份基礎

加密領域自主研究指南(DYOR)
