Na prática, quando um programador ou utilizador apresenta um pedido de IA, não recebe um resultado não verificável de imediato. O processo inicia-se, sim, num fluxo de trabalho com várias fases—computação, verificação e registo—que garantem resultados fiáveis. Esta estrutura é fundamental para decisões automatizadas e processamento de dados.
O fluxo de trabalho inclui habitualmente entrada do pedido, execução da inferência, verificação do resultado e confirmação on-chain. A colaboração entre estes módulos define a lógica operacional da OpenGradient.
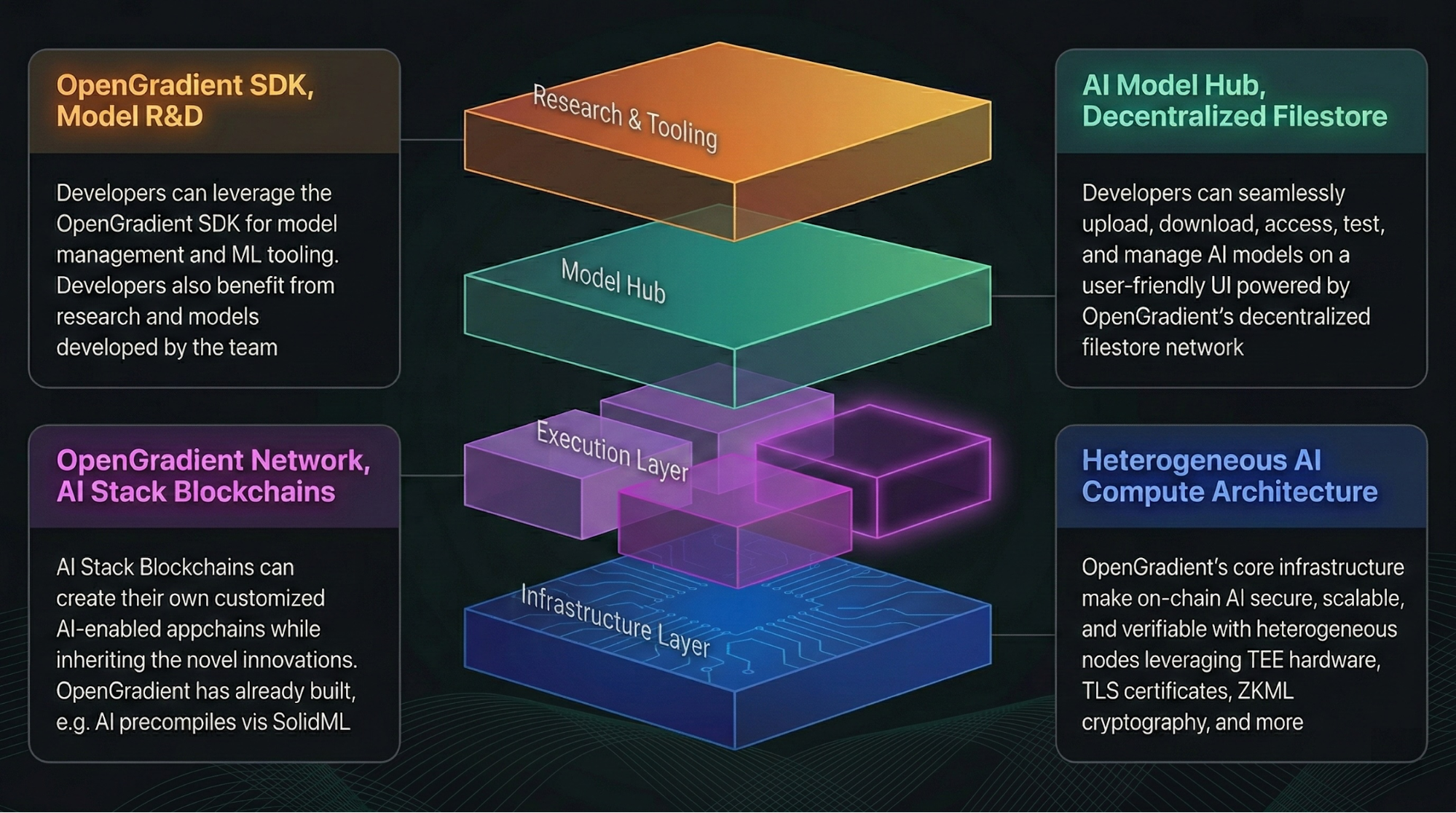
Como os Utilizadores se Ligam à Rede OpenGradient
O acesso do utilizador dá início a todo o processo.
Do ponto de vista técnico, os programadores integram as aplicações na rede OpenGradient através de uma API ou SDK, submetendo pedidos de inferência com parâmetros do modelo e dados de entrada. Após a receção do pedido, o sistema formata e prepara-o para atribuição.
A camada de acesso situa-se na periferia da rede, transformando pedidos dos utilizadores em tarefas internas executáveis e encaminhando-as para o sistema de agendamento. Esta camada integra normalmente serviços de interface e módulos de gestão de pedidos.
Este modelo oculta a complexidade da computação distribuída por trás de uma interface unificada, permitindo aos utilizadores explorar a rede sem necessidade de conhecer a arquitetura subjacente.
Como São Submetidos os Pedidos de IA na OpenGradient
A fase de submissão do pedido define o modo como as tarefas entram na linha de execução.
Assim que um pedido é recebido, o sistema atribui-o ao nó de inferência mais adequado, consoante o tipo de tarefa, a complexidade e o estado do nó. Algoritmos de agendamento otimizam a utilização dos recursos ao longo deste processo.
O módulo de gestão de pedidos regista os detalhes da tarefa e gera um identificador único para rastreio e verificação. De seguida, a tarefa entra na fila de execução, aguardando processamento pelo nó de inferência.
Este mecanismo permite um agendamento centralizado, garantindo uma alocação eficiente de recursos e evitando congestionamentos nos nós.
Como os Nós de Inferência Realizam a Computação do Modelo
Os nós de inferência executam as operações computacionais.
Quando recebem uma tarefa, os nós de inferência processam o modelo de IA localmente, analisam os dados de entrada e produzem os resultados. Para garantir verificabilidade, geram também dados de prova associados.
Estes nós incluem o ambiente de execução do modelo e um módulo de geração de resultados, operando normalmente em ambientes controlados para assegurar estabilidade e reprodutibilidade.
Esta etapa garante que computação e geração de provas decorrem simultaneamente, estabelecendo as bases para a verificação posterior.
Como os Nós de Verificação Validam os Resultados de Inferência
Os nós de verificação asseguram a integridade e confiança dos resultados.
Recebem os dados de saída e de prova dos nós de inferência e verificam de forma independente a sua correção, recorrendo a algoritmos de computação ou validação. Caso a validação falhe, o resultado é rejeitado ou recalculado.
A camada de verificação funciona independentemente da camada de execução, garantindo que a validação não depende dos nós de computação originais e reforçando a segurança do sistema.
Este mecanismo transfere a confiança de um nó individual para a rede, proporcionando resistência a manipulações.
Como o Registo On-Chain Garante a Confirmação Final
O registo on-chain fixa o resultado final de forma permanente.
Depois de verificados, os resultados são submetidos à blockchain (ou camada de dados relacionada), criando uma prova de execução imutável. Normalmente, este processo inclui a embalagem dos dados e etapas de confirmação.
A camada on-chain localiza-se no final do processo, registando os resultados no livro-razão distribuído para garantir rastreabilidade a longo prazo.
Esta arquitetura assegura que os resultados computacionais são persistentes e auditáveis, possibilitando consultas e análises futuras.
Como os Módulos Colaboram para Concluir a Execução
A eficiência global do sistema depende da colaboração entre módulos.
As camadas de pedido, execução, verificação e registo comunicam através de passagem de mensagens e agendamento de tarefas, com cada fase a entregar resultados à seguinte.
Os módulos dispõem-se em pipeline, permitindo o processamento contínuo de tarefas sem estrangulamentos.
| Módulo |
Função |
Posição |
| Camada de Acesso |
Recebe Pedidos |
Ponto de Entrada |
| Camada de Agendamento |
Aloca Tarefas |
Intermédia |
| Nó de Inferência |
Executa Computação |
Núcleo |
| Nó de Verificação |
Valida Resultados |
Camada de Segurança |
| Camada On-Chain |
Regista Resultados |
Ponto Final |
Esta cooperação aumenta o throughput e assegura responsabilidades claras em cada etapa.
Estrutura Sequencial do Fluxo de Inferência OpenGradient
Todo o fluxo de trabalho pode ser segmentado em etapas sequenciais.
Uma tarefa típica segue a sequência: submissão do pedido → alocação da tarefa → execução do modelo → geração de resultados → verificação → registo on-chain. Estas etapas constituem um circuito fechado.
Cada fase é gerida por um módulo distinto, garantindo responsabilidade clara e escalabilidade do sistema.
Ao dividir o processo em etapas padronizadas, aumenta-se a manutenção e expandem-se as capacidades do sistema.
Resumo
A OpenGradient permite computação verificável ao segmentar a inferência de IA, verificação de resultados e registo on-chain em módulos colaborativos. Esta estrutura potencia eficiência e confiança em redes de IA descentralizadas.
FAQ
Como é que a OpenGradient processa pedidos de IA?
Quando o utilizador submete um pedido, o sistema atribui-o a nós de inferência para execução, iniciando depois o processo de verificação.
Porque são necessários nós de verificação?
Validam os resultados de inferência de forma independente, eliminando a dependência de qualquer nó individual.
Qual é o papel do registo on-chain?
Preserva o resultado final, garantindo imutabilidade e auditabilidade.
Qual a diferença entre nós de inferência e nós de verificação?
Os nós de inferência executam as computações; os nós de verificação confirmam a correção dos resultados.
Porque é que a OpenGradient utiliza um fluxo de trabalho em várias etapas?
Um processo por fases aumenta a eficiência e reforça a segurança, permitindo que cada módulo se dedique a tarefas especializadas.








