AI 交易的数据底座:你该喂给模型什么?
本课将从“数据如何决定策略上限”出发,系统拆解 AI 加密交易所需的数据类型、特征构建方法与常见数据陷阱,帮助学习者建立可用于实盘的研究起点。
在第一课中,我们讲了 AI 为什么会成为加密交易的新基础设施。接下来的关键问题是:AI 再强,也只能在你提供的数据边界内工作。
很多策略失败,不是模型不够复杂,而是数据层已经出现了方向性错误:要么数据质量不足,要么特征设计失真,要么验证方式有偏差。
因此,真正的 AI 交易往往不是从“选模型”开始,而是从“搭数据底座”开始。你喂给模型什么,决定了它能看见什么;它能看见什么,决定了它能做出什么判断。
一、先建立一个共识:数据不是越多越好,而是越“有因果结构”越好
刚接触 AI 的交易者容易陷入“数据囤积”思维:把能抓到的数据都抓进来,认为特征越多越容易出 alpha。
现实中,低质量、多噪声、弱相关的数据反而会降低模型稳定性。原因很简单:
- 模型会在噪声里“学到假规律”;
- 样本外环境变化时,假规律最先失效;
- 特征越冗余,策略越难解释和维护。
所以,搭建数据体系的第一原则是:
围绕交易问题选数据,而不是围绕数据本身找问题。
如果你要解决的是“短周期方向判断”,就优先关注微观结构与情绪冲击;如果你要做的是“中周期仓位管理”,就更应关注流动性、波动结构与宏观因子。
二、AI 加密交易的四类核心数据源
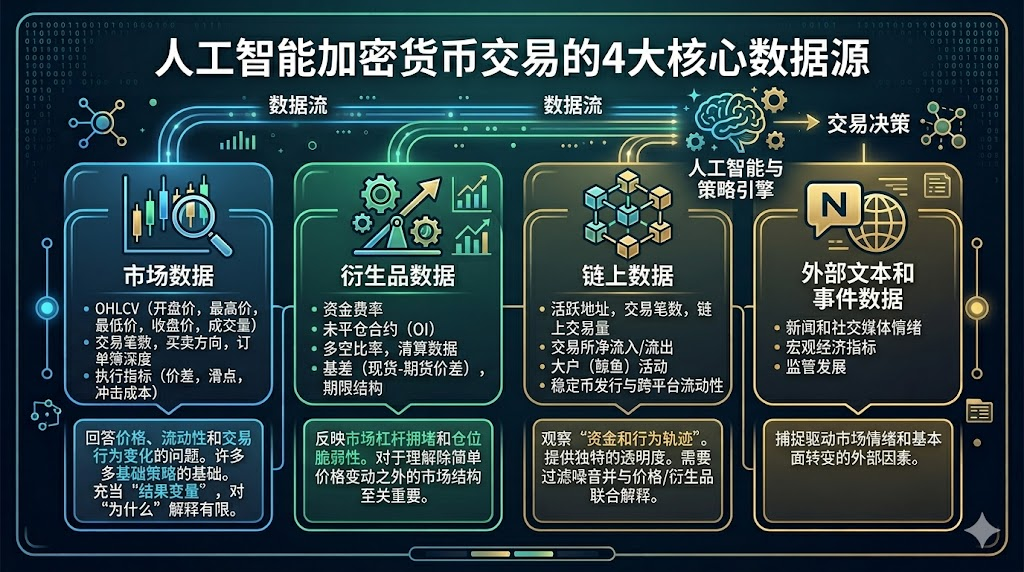
在加密市场里,最有价值的数据通常来自四个层面:行情、衍生品、链上与外部信息。
行情数据(Market Data)
这是所有策略的基础层,包括:
- OHLCV(开高低收量)
- 成交笔数、买卖方向、盘口深度
- 点差、滑点、冲击成本等执行相关指标
它回答的问题是:价格如何变化、流动性如何变化、成交行为如何变化。
很多基础策略只用行情数据就可以建立,但它的局限是:更像“结果变量”,对“为什么变化”解释能力有限。
衍生品数据(Derivatives Data)
在加密市场尤其关键,包括:
- 资金费率(Funding Rate)
- 未平仓合约(Open Interest)
- 多空账户比、清算数据
- 基差(现货-合约价差)、期限结构
这类数据能反映市场杠杆拥挤度和仓位脆弱性。
例如,“价格上涨 + OI 同步上升 + 资金费率偏高”与“价格上涨 + OI 下降”的含义完全不同。前者可能是趋势强化,也可能是杠杆拥挤;后者更可能是空头回补驱动。
没有衍生品维度,你很难判断行情背后的仓位结构。
链上数据(On-chain Data)
这是加密市场区别于传统市场的重要优势,包括:
- 活跃地址、交易笔数、链上转账规模
- 交易所净流入/流出
- 大额地址(鲸鱼)行为
- 稳定币发行与跨平台流动
链上数据的价值在于能观察“资金与行为轨迹”,但难点在于解释滞后和噪声过滤。
同样是交易所流入增加,可能是抛压准备,也可能是对冲准备。链上数据必须与价格结构和衍生品数据联合解释,单独使用容易误判。
外部文本与事件数据(News/Social/Macro)
包括新闻、社媒讨论热度、政策事件、宏观数据发布时间点等。
它们更像“冲击源数据”:解释波动为何突然放大,或趋势为何在短时转向。
但这类数据问题也最明显:主观性强、噪声高、真假信息混杂。
因此,外部文本更适合做“风险提示因子”和“事件过滤器”,不建议直接作为唯一入场信号。
三、从原始数据到可交易特征:特征工程才是策略分水岭
AI 不直接理解“市场叙事”,它只识别特征模式。
所以第二步不是急着训练模型,而是把原始数据变成可学习、可验证、可交易的特征。
常见可用特征可以分四组:
- 趋势特征:动量、均线斜率、突破强度
- 波动特征:历史波动率、区间振幅、波动率突变
- 结构特征:资金费率偏离、OI变化率、基差变化
- 行为特征:链上净流向变化、新闻情绪冲击、社媒热度异常
关键不在“特征多炫”,而在三个标准:
- 是否有经济意义(不是纯数学拼接);
- 是否可在真实时间点获得(无未来信息);
- 是否能穿越不同市场阶段(牛熊震荡不过度失真)。
四、标签设计:你让模型预测什么,决定了它学到什么
很多人默认让模型预测“下一根 K 线涨跌”,但这并不一定是最优任务。
交易目标可以有很多种标签形式:
- 分类标签:未来 n 周期收益是否超过阈值
- 回归标签:未来 n 周期收益率
- 风险标签:未来 n 周期是否出现大幅回撤
- 结构标签:未来波动是否扩张、资金费率是否极端
如果你的策略目标是“避开大回撤”,却用“短线涨跌”做标签,模型再准确也未必有用。
所以标签应与策略目标一致:交易要赚什么钱,就让模型学习什么目标。
五、数据验证的关键:时间序列世界里,验证方式比模型更重要
在普通机器学习任务里,随机打乱训练集与测试集常见且合理;但在交易里这么做会严重失真。
因为市场有时间依赖结构,未来信息绝不能“泄漏”到过去。
AI 交易至少要坚持三条验证纪律:
- 时间切分训练/验证/测试,避免随机打乱;
- 样本外验证必须覆盖不同波动环境;
- 滚动窗口(Walk-forward)模拟真实上线过程。
很多“回测神策略”崩盘,根因不是市场变坏,而是测试方法一开始就乐观偏置。
六、最常见的五类数据陷阱
时间穿越(Look-ahead Bias)
使用了当时不可得的数据,导致结果虚高。
幸存者偏差(Survivorship Bias)
只用“活下来的币种或平台”训练,忽略失败样本。
过度清洗(Over-cleaning)
把真实噪声当脏数据删除,模型失去对极端行情的适应力。
特征泄漏(Leakage)
特征里隐含了标签信息,让模型看起来过度准准。
频率错配(Frequency Mismatch)
把低频链上特征硬套到高频交易任务,造成伪信号。
这些问题不会在回测里主动报警,但会在实盘里迅速放大。
一个实用的数据工作流:先小而稳,再扩展
对课程学习者而言,最稳妥的做法不是一上来就做“全市场全因子大模型”,而是从最小可行数据框架开始:
- 选单一标的(如 BTC 或 ETH)
- 先用行情 + 衍生品两类数据
- 做 10-20 个有经济解释的基础特征
- 设计一个明确标签(如未来 4 小时收益是否>0)
- 时间序列验证 + 滚动测试
- 再逐步加入链上与文本因子
这样做的好处是:问题定位清晰、迭代成本低、上线路径短。
复杂系统不是一开始就做出来的,而是在可解释的小系统上逐层扩展出来的。
Gate for AI 在数据层的现实意义
在实际落地中,数据环节常常是最耗时的部分:多源采集、格式清洗、时间对齐、特征流水线、策略联调。
这也是为什么平台化 AI 工具越来越重要。以 Gate for AI 这一类基础设施为例,其价值不在“替你生成一个万能策略”,而在于帮助交易者更高效地完成从数据到策略的工程闭环,降低研究到执行之间的摩擦成本。交易者仍然要定义问题、设定约束、管理风险,但底层工作流可以更标准、更可复用。
相关课程

Aethir 介绍

加密货币领域的身份验证项目概览

加密领域自主研究指南(DYOR)
稳定币基础