DegenSing
Web3 Degen | 通貨分析 & トレーディングインサイト | #メモコイントレーダー
DegenSing
チームを雇うことは忘れてください。2026年にSaaSをソロで運営するための完全なスタックはここです:
→ n8n.. アプリを接続し、ワークフローを自動化
→ Supabase.. データベース、認証、API
→ Cursor.. AI搭載コードエディタ
→ Claude.. 計画、デバッグ、推論
→ Vercel.. ホストとインスタント展開
→ Stripe..
原文表示→ n8n.. アプリを接続し、ワークフローを自動化
→ Supabase.. データベース、認証、API
→ Cursor.. AI搭載コードエディタ
→ Claude.. 計画、デバッグ、推論
→ Vercel.. ホストとインスタント展開
→ Stripe..
- 報酬
- 2
- コメント
- リポスト
- 共有
このウィークエンドでAIでできる最高ROIのこと。各カテゴリーから1つ選んでください。月曜日までに99%の人より先を行けます。無料のAIコース (~3時間各): → Claude Code: → OpenClaw: → Claude Cowork:
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
チームを雇うのは忘れてください。
ここに2026年にSaaSをソロで運営するための完全なスタックがあります:
→ n8n.. アプリを接続しワークフローを自動化
→ Supabase.. データベース、認証、API
→ Cursor.. AI搭載コードエディタ
→ Claude.. 計画、デバッグ、推論
→ Vercel.. ホスティングと即座にデプロイ
→ Stripe.. サブスクリプション&グローバル決済
→ Resend.. トランザクションメール
→ Framer.. マーケティングページを数分で作成
→ PostHog.. プロダクト分析とユーザー追跡
→ Cloudflare.. CDN、セキュリティ、キャッシング
これらすべてに無料ティアがあります。
月額$0、稼ぐまで無料。言い訳の余地がありません。
原文表示ここに2026年にSaaSをソロで運営するための完全なスタックがあります:
→ n8n.. アプリを接続しワークフローを自動化
→ Supabase.. データベース、認証、API
→ Cursor.. AI搭載コードエディタ
→ Claude.. 計画、デバッグ、推論
→ Vercel.. ホスティングと即座にデプロイ
→ Stripe.. サブスクリプション&グローバル決済
→ Resend.. トランザクションメール
→ Framer.. マーケティングページを数分で作成
→ PostHog.. プロダクト分析とユーザー追跡
→ Cloudflare.. CDN、セキュリティ、キャッシング
これらすべてに無料ティアがあります。
月額$0、稼ぐまで無料。言い訳の余地がありません。
- 報酬
- 2
- コメント
- リポスト
- 共有
このウィークエンドに取り組むべき最高ROIのAIのこと。
各カテゴリーから1つだけ選んでください。月曜日までにあなたは99%の人より先を行きます。
無料AIコース (~3時間ずつ):
→ Claude Code:
→ OpenClaw:
→ Claude Cowork:
→ Google Antigravity:
AIスキル (任意のLLMを開いて学習を始めてください):
→ プロンプトエンジニアリング
→ コンテキスト管理の基礎
→ エリート出力のためのモデルスタッキング
→ バイブコーディング基礎
オートメーション設定:
→ OpenClaw
→ Perplexity Computer
→ Manus
日常の主力ツール:
→ Claude app + Cowork
→ Notionデータベースエージェント (新機能)
→ コンテキストファイル付きChatGPT projects
→ Gemini Gems
→ パーソナルAI第二の脳 (Mem、Notion AI、またはObsidian + AIプラグイン)
1ウィークエンド。4カテゴリー。各カテゴリーから1つ選ぶ。
以上です。さあ、構築しましょう。
原文表示各カテゴリーから1つだけ選んでください。月曜日までにあなたは99%の人より先を行きます。
無料AIコース (~3時間ずつ):
→ Claude Code:
→ OpenClaw:
→ Claude Cowork:
→ Google Antigravity:
AIスキル (任意のLLMを開いて学習を始めてください):
→ プロンプトエンジニアリング
→ コンテキスト管理の基礎
→ エリート出力のためのモデルスタッキング
→ バイブコーディング基礎
オートメーション設定:
→ OpenClaw
→ Perplexity Computer
→ Manus
日常の主力ツール:
→ Claude app + Cowork
→ Notionデータベースエージェント (新機能)
→ コンテキストファイル付きChatGPT projects
→ Gemini Gems
→ パーソナルAI第二の脳 (Mem、Notion AI、またはObsidian + AIプラグイン)
1ウィークエンド。4カテゴリー。各カテゴリーから1つ選ぶ。
以上です。さあ、構築しましょう。
- 報酬
- 2
- コメント
- リポスト
- 共有
I'm ready to help you translate cryptocurrency, Web3, and financial content to Japanese. However, I don't see any text to translate in your message.
Please provide the content you'd like me to translate, and I'll translate it while:
- Preserving all numeric digits (0-9)
- Keeping placeholders like , @E5@ exactly as they appear
- Maintaining mixed content formatting
Go ahead and share the text you need translated!
原文表示Please provide the content you'd like me to translate, and I'll translate it while:
- Preserving all numeric digits (0-9)
- Keeping placeholders like , @E5@ exactly as they appear
- Maintaining mixed content formatting
Go ahead and share the text you need translated!
- 報酬
- 1
- コメント
- リポスト
- 共有
誰も簡単に説明しない、すべてのVibeコーダーが理解すべきこと: → API..サーバー同士の通信 → .env..秘密情報が保存される場所 (絶対にpushしないで) → localhost..自分のマシンがサーバーのように動作する → auth..主にトークンとクッキー → npm install..1万以上のパッケージをインストール
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
正直な質問です。
もしAIが80%のコードを書いているとしたら、開発者はコーダーではなくディレクターになってしまうのでしょうか?
実際、今まさにそうなりつつあります。私はコードを書くよりも、レビューしたり、指示を出したり、プロンプトを考えたりする時間の方が圧倒的に多いです。
仕事はもはや「コードを書く」ことではなく、「何を作るかを理解し、AIに正しく作らせる方法を伝える」ことになっています。
それはまだエンジニアリングと呼べるのでしょうか、それとも端末を開いたままのプロダクトマネジメントなのでしょうか?
原文表示もしAIが80%のコードを書いているとしたら、開発者はコーダーではなくディレクターになってしまうのでしょうか?
実際、今まさにそうなりつつあります。私はコードを書くよりも、レビューしたり、指示を出したり、プロンプトを考えたりする時間の方が圧倒的に多いです。
仕事はもはや「コードを書く」ことではなく、「何を作るかを理解し、AIに正しく作らせる方法を伝える」ことになっています。
それはまだエンジニアリングと呼べるのでしょうか、それとも端末を開いたままのプロダクトマネジメントなのでしょうか?
- 報酬
- 2
- コメント
- リポスト
- 共有
Anthropic がプロンプトエンジニアリングについてのマスタークラスを静かにリリースしました。これらのヒントを実装した後、私のClaude応答は一晩で6.5/10から9.5/10に改善されました。Claudeを定期的に使用している場合は、このプロンプティングブループリントを参考にしてください:
> ステップ1:タスクコンテキスト ロールと全体的なタスクを定義する
原文表示> ステップ1:タスクコンテキスト ロールと全体的なタスクを定義する
- 報酬
- 1
- コメント
- リポスト
- 共有
すべてのバイブコーダーが理解すべき but nobody explains simply:
→ API.. サーバー同士の通信
→ .env.. 秘密情報が保存されている場所 (絶対にプッシュしない)
→ localhost.. 自分のマシンがサーバーのように動作する
→ 認証.. 主にトークン + クッキー
→ npm install.. 自分が書いていない1万のパッケージをインストール
→ フロントエンド.. HTTPリクエストを送るだけ
→ データベース.. 構造化されたデータ + クエリ
→ レートリミット.. APIのスパムを防ぐ
これを理解すれば.. ウェブ開発は突然ずっと簡単になる。
あなたはCSの学位を持つ必要はない。これら8つの概念と週末だけあれば十分。
原文表示→ API.. サーバー同士の通信
→ .env.. 秘密情報が保存されている場所 (絶対にプッシュしない)
→ localhost.. 自分のマシンがサーバーのように動作する
→ 認証.. 主にトークン + クッキー
→ npm install.. 自分が書いていない1万のパッケージをインストール
→ フロントエンド.. HTTPリクエストを送るだけ
→ データベース.. 構造化されたデータ + クエリ
→ レートリミット.. APIのスパムを防ぐ
これを理解すれば.. ウェブ開発は突然ずっと簡単になる。
あなたはCSの学位を持つ必要はない。これら8つの概念と週末だけあれば十分。
- 報酬
- 2
- コメント
- リポスト
- 共有
Anthropicが静かにプロンプトエンジニアリングのマスタークラスをリリースしました。
これらのコツを実装した後、私のClaudeの回答は一晩で6.5/10から9.5/10に跳ね上がりました。
Claudeを定期的に使用している場合は、このプロンプティングブループリントを盗んでください:
> ステップ1:タスクコンテキスト
役割と全体的なタスクを事前に定義してください。「メールを書いてください」と言うだけでなく、「あなたはシニアマーケティング戦略家です。B2B SaaS製品をターゲットとしたCFO向けのコールドアウトリーチメールを書いてください」と言ってください。
役割が具体的なほど、出力が良くなります。毎回です。
> ステップ2:トーンコンテキスト
コミュニケーション スタイルを明示的に設定してください。プロフェッショナル、カジュアル、テクニカル、フレンドリー、扇動的など。Claudeはすぐに適応しますが、あなたが指示した場合のみです。
> ステップ3:背景データ
関連ファイルを添付するか、サポートコンテンツに貼り付けてください。Claudeはあなたの心を読むことはできませんが、ドキュメントを読むことはできます。すべてを入力してください。
> ステップ4:詳細なタスク説明とルール
制約と期待を展開してください。「200語以下に保つ。専門用語なし。能動態を使用。1つの具体的な例を
原文表示これらのコツを実装した後、私のClaudeの回答は一晩で6.5/10から9.5/10に跳ね上がりました。
Claudeを定期的に使用している場合は、このプロンプティングブループリントを盗んでください:
> ステップ1:タスクコンテキスト
役割と全体的なタスクを事前に定義してください。「メールを書いてください」と言うだけでなく、「あなたはシニアマーケティング戦略家です。B2B SaaS製品をターゲットとしたCFO向けのコールドアウトリーチメールを書いてください」と言ってください。
役割が具体的なほど、出力が良くなります。毎回です。
> ステップ2:トーンコンテキスト
コミュニケーション スタイルを明示的に設定してください。プロフェッショナル、カジュアル、テクニカル、フレンドリー、扇動的など。Claudeはすぐに適応しますが、あなたが指示した場合のみです。
> ステップ3:背景データ
関連ファイルを添付するか、サポートコンテンツに貼り付けてください。Claudeはあなたの心を読むことはできませんが、ドキュメントを読むことはできます。すべてを入力してください。
> ステップ4:詳細なタスク説明とルール
制約と期待を展開してください。「200語以下に保つ。専門用語なし。能動態を使用。1つの具体的な例を

- 報酬
- 1
- 1
- リポスト
- 共有
ybaser :
:
月へ 🌕これが私が今探していたものです。これでより良いプレゼンテーションが作れます。インタラクティブにしてみてください。クライアントはきっとこの仕事を気に入るでしょう。愛してるよ、Claude!
原文表示- 報酬
- 1
- コメント
- リポスト
- 共有
私はそのようなコードを「ノリで書いて」1~2時間で製品をリリースできる人たちが誰なのかわかりません...製品レディなV1を作成して出荷するには、私は少なくとも2~3日必要です。
原文表示- 報酬
- 1
- コメント
- リポスト
- 共有
私はそのようなコードをバイブさせて1~2時間で製品を出荷できる人たちが誰なのか知りません...
本番環境対応のV1を出荷して動作させるには、少なくとも2~3日かかります。
原文表示本番環境対応のV1を出荷して動作させるには、少なくとも2~3日かかります。
- 報酬
- いいね
- コメント
- リポスト
- 共有
誰も話していませんが、ヴァイブコーディングは意図せずにほとんどのブートキャンプより多くのことを人々に教えています。あなたがビルドを始めると、気付かないうちに以下を学びます:APIがすべてをどのように接続するのか、あなたの.envファイルが実際に重要な理由、localhostが本当に何を意味するのか、なぜローカルで動作するのに
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
ついに本当に重要なベンチマークが登場した。MMULUと数学スコアは忘れよう。PinchBenchは、AIモデルが実際の仕事をするのにどれが最適かをテストする。トリビアに答えるのではなく、実際のことをやること:
→ 複数のウェブソースから情報を検索する
→ ミーティングを作成してスケジュール設定する
→ 整理する
原文表示→ 複数のウェブソースから情報を検索する
→ ミーティングを作成してスケジュール設定する
→ 整理する
- 報酬
- いいね
- コメント
- リポスト
- 共有
誰も話題にしていませんが、ビブコーディングはほとんどのブートキャンプより多くのことを人々に誤って教えています。
構築を始めると、気づかないうちに以下を学びます:
APIがすべてをどのようにつなぐのか
.envファイルが実際に重要な理由
localhostが本当に何を意味するのか
ローカルで動作するのにデプロイで機能が壊れる理由
認証が内部でどのように実際に動作するのか
npm installの後に本当に何が起こるのか
バックエンドロジックがどのように流れるのか
データベースがどのように構築されているのか
レート制限が存在する理由
ビブコーディングは学習をスキップしていません。単に順序を変えているだけです。
原文表示構築を始めると、気づかないうちに以下を学びます:
APIがすべてをどのようにつなぐのか
.envファイルが実際に重要な理由
localhostが本当に何を意味するのか
ローカルで動作するのにデプロイで機能が壊れる理由
認証が内部でどのように実際に動作するのか
npm installの後に本当に何が起こるのか
バックエンドロジックがどのように流れるのか
データベースがどのように構築されているのか
レート制限が存在する理由
ビブコーディングは学習をスキップしていません。単に順序を変えているだけです。
- 報酬
- いいね
- コメント
- リポスト
- 共有
Claudeは文字通りあなたを裕福にすることができます。投資会社、銀行、金融機関はすべてClaudeを使って調査と分析を行っています。そして今、あなたも彼らの正確な戦略を盗むことができます。以下は、Claudeを使ったトップ金融機関が採用している9段階のシステムです: > フェーズ1:あなたの構築
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
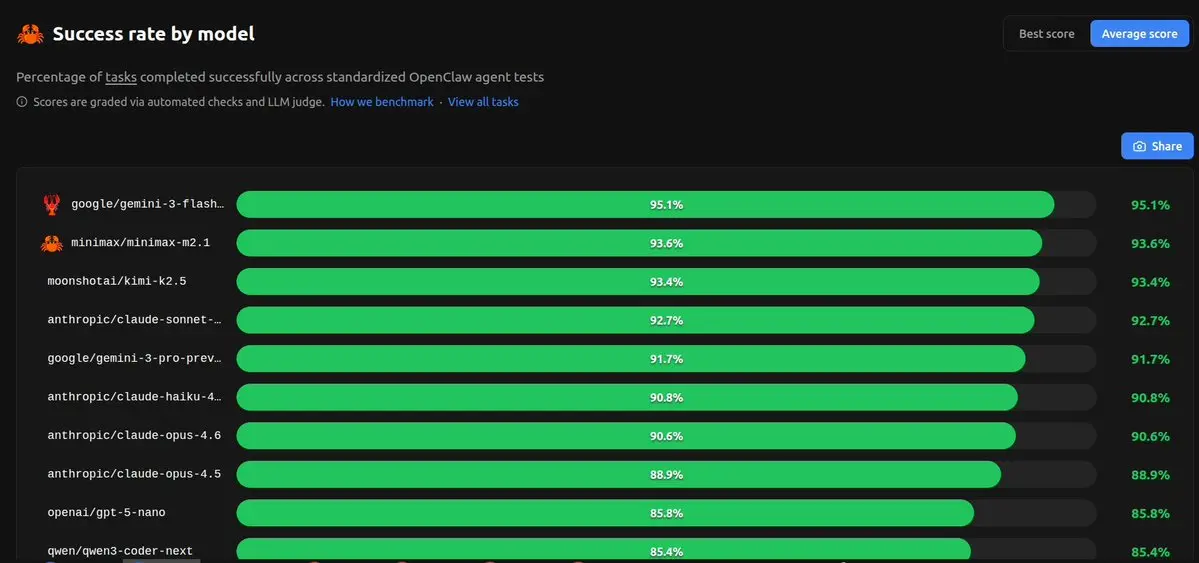
ついに実際に重要なベンチマークが登場。
MMLUや数学スコアは忘れてください。PinchBenchは、AIモデルが実際の作業をどれだけこなせるかを測定します。
クイズに答えるだけではなく、実際に行動すること:
→ 複数のWebソースから情報を検索
→ 会議の作成とスケジューリング
→ コンピュータ上のファイル整理
→ メールの作成と管理
これらは、OpenClawを通じてエージェントとして動作するモデルをテストしています。つまり、AIはツールを使い、アクションを連鎖させ、タスクをエンドツーエンドで完了させる必要があります。
結果は興味深いです:
> Gemini 3 Flashが95.1%でリード
> MiniMax M2.1が93.6%で追従
> Kimi K2.5が93.4%
> Claude Sonnetが92.7%
> Gemini 3 Proが91.7%
> Claude Haikuが90.8%
> Claude Opus 4.6が90.6%
> GPT-5 Nanoが85.8%
トップとボトムの差はわずか約10%…つまり、多くの最先端モデルがエージェントタスクにかなり適応してきていることを示しています。
しかし、真のポイントは?軽量モデルのGemini Flashが、重いモデルを凌駕して実用的なエージェント作業をこなしていることです。速度+ツール使用 > 純粋な知性。
原文表示MMLUや数学スコアは忘れてください。PinchBenchは、AIモデルが実際の作業をどれだけこなせるかを測定します。
クイズに答えるだけではなく、実際に行動すること:
→ 複数のWebソースから情報を検索
→ 会議の作成とスケジューリング
→ コンピュータ上のファイル整理
→ メールの作成と管理
これらは、OpenClawを通じてエージェントとして動作するモデルをテストしています。つまり、AIはツールを使い、アクションを連鎖させ、タスクをエンドツーエンドで完了させる必要があります。
結果は興味深いです:
> Gemini 3 Flashが95.1%でリード
> MiniMax M2.1が93.6%で追従
> Kimi K2.5が93.4%
> Claude Sonnetが92.7%
> Gemini 3 Proが91.7%
> Claude Haikuが90.8%
> Claude Opus 4.6が90.6%
> GPT-5 Nanoが85.8%
トップとボトムの差はわずか約10%…つまり、多くの最先端モデルがエージェントタスクにかなり適応してきていることを示しています。
しかし、真のポイントは?軽量モデルのGemini Flashが、重いモデルを凌駕して実用的なエージェント作業をこなしていることです。速度+ツール使用 > 純粋な知性。
- 報酬
- いいね
- コメント
- リポスト
- 共有
Claudeは文字通りあなたを裕福にすることができます。
投資会社、銀行、金融機関はすべてClaudeを研究と分析に利用しています。
そして今、あなたは彼らの正確なプレイブックを盗むことができます。
以下は、Claudeを使ったトップ金融機関が採用している9段階のシステムです:
> フェーズ1:投資家プロフィールの作成
Claudeにあなたのスタイルを伝えましょう (価値、成長、マクロ)、リスク許容度、投資期間、リターン目標。これが以降すべての視点のレンズとなります。
プロンプト:「こちらが私の投資家プロフィールです。今日議論するすべてのことの参考にしてください。」
> フェーズ2:機関文書の分析
10-K、決算発表、ヘッジファンドのレター、M&A申請書をアップロード。Claudeはマージンのコメント、リスクの兆候、FCFの言及、四半期ごとのガイダンスの比較を抽出します。
> フェーズ3:詳細な企業調査
ビジネスモデルを簡単に説明.. moatの耐久性.. 上位3つの競合他社.. 経営陣の実績.. サプライチェーンの露出。1つのプロンプトでアナリストが1週間費やす内容を提供します。
> フェーズ4:仮説のストレステスト
ここで多くの人がスキップして損失を出します。最も強力なベアケース5つを生成。ショートの論点を鋼鉄化。投資をゼロにする要因を定義します。
プロのヒント:資本を投入する
原文表示投資会社、銀行、金融機関はすべてClaudeを研究と分析に利用しています。
そして今、あなたは彼らの正確なプレイブックを盗むことができます。
以下は、Claudeを使ったトップ金融機関が採用している9段階のシステムです:
> フェーズ1:投資家プロフィールの作成
Claudeにあなたのスタイルを伝えましょう (価値、成長、マクロ)、リスク許容度、投資期間、リターン目標。これが以降すべての視点のレンズとなります。
プロンプト:「こちらが私の投資家プロフィールです。今日議論するすべてのことの参考にしてください。」
> フェーズ2:機関文書の分析
10-K、決算発表、ヘッジファンドのレター、M&A申請書をアップロード。Claudeはマージンのコメント、リスクの兆候、FCFの言及、四半期ごとのガイダンスの比較を抽出します。
> フェーズ3:詳細な企業調査
ビジネスモデルを簡単に説明.. moatの耐久性.. 上位3つの競合他社.. 経営陣の実績.. サプライチェーンの露出。1つのプロンプトでアナリストが1週間費やす内容を提供します。
> フェーズ4:仮説のストレステスト
ここで多くの人がスキップして損失を出します。最も強力なベアケース5つを生成。ショートの論点を鋼鉄化。投資をゼロにする要因を定義します。
プロのヒント:資本を投入する

- 報酬
- 1
- コメント
- リポスト
- 共有