TheFatCatThatDoesn_tChange
現在、コンテンツはありません
TheFatCatThatDoesn_tChange
3年多前、私がSovitsを使っていた頃、その時の音声モデルは背景音を分離(環境音を除去)してクリーンな声だけを抽出し、トレーニングを行う必要がありました。
そして、データセットを選別し、ノイズの多い部分を除去してからトレーニングを開始します。
一般的に8000ステップ程度のトレーニングで音色の再現度が最も良くなりますが、8000ステップを超えても評価点が25以下のままだと、そのデータセットとトレーニングはほぼ無意味になります。もし無理に続けて14000ステップを超えると、「発散」と呼ばれる現象が起き、最終的に生成される音声は「電音がひどい」か「人間らしさが失われている」状態になります。
これはまるで量子取引の開発ステップのように見えます。クリーンな声を抽出する過程は、機械に自己学習と予測モデルのためのデータセットを見つけさせる作業であり、ノイズの多い部分を除去するのは、無効な市場(1分間の急騰・暴落部分)をフィルタリングすることに似ています。8000ステップのトレーニングでは過剰適合(オーバーフィッティング)が起きにくく、14000ステップを超えて「発散」する(過剰適合する)と、最終的には実取引の結果がコイン投げのようにランダムになることに近づきます。
たとえ異なる分野に見えても、根底にある論理は同じです。
将来的に、私たちを打ち負かすのは業界そのものの
原文表示そして、データセットを選別し、ノイズの多い部分を除去してからトレーニングを開始します。
一般的に8000ステップ程度のトレーニングで音色の再現度が最も良くなりますが、8000ステップを超えても評価点が25以下のままだと、そのデータセットとトレーニングはほぼ無意味になります。もし無理に続けて14000ステップを超えると、「発散」と呼ばれる現象が起き、最終的に生成される音声は「電音がひどい」か「人間らしさが失われている」状態になります。
これはまるで量子取引の開発ステップのように見えます。クリーンな声を抽出する過程は、機械に自己学習と予測モデルのためのデータセットを見つけさせる作業であり、ノイズの多い部分を除去するのは、無効な市場(1分間の急騰・暴落部分)をフィルタリングすることに似ています。8000ステップのトレーニングでは過剰適合(オーバーフィッティング)が起きにくく、14000ステップを超えて「発散」する(過剰適合する)と、最終的には実取引の結果がコイン投げのようにランダムになることに近づきます。
たとえ異なる分野に見えても、根底にある論理は同じです。
将来的に、私たちを打ち負かすのは業界そのものの
- 報酬
- いいね
- コメント
- リポスト
- 共有
人家都是越过越好,我是原地踏步😂···
2023年的第一间办公室,月租2700,因为没暖气,冬天实在太冷,从租回来到退租,我一共就去了3次😂,电脑都冻的开不了机😂···
2024年的社区办公室,这里真的承载了太多的回忆了,有欢乐有痛苦也有不甘····月租3000,因为房东“脑子有病”(暖气管道漏了不修,导致供暖期会停电)退租了,这是我待的时间最长的地方,我在这间办公室待的时间比我在家里待的时间还要长···
2025年的社区办公室,吸取了上一次的教训,不租了,直接买下来了,连装修用了大概64,又是啃老本买的,交易圈啊交易圈,真的是路漫漫其修远兮···
今天上午一个以前一起做外包的朋友来电话,说准备退休了,已经捞够了,问我怎么样,我都不知道该怎么回答😂,照实说,会显得我很蠢,不照实说又没意思,支支吾吾之后,朋友也明白了,大概率我还在原地转圈····
其实这样也挺好,吃的下,睡的着,不坑不骗,不用担心“鬼上门”···
原文表示2023年的第一间办公室,月租2700,因为没暖气,冬天实在太冷,从租回来到退租,我一共就去了3次😂,电脑都冻的开不了机😂···
2024年的社区办公室,这里真的承载了太多的回忆了,有欢乐有痛苦也有不甘····月租3000,因为房东“脑子有病”(暖气管道漏了不修,导致供暖期会停电)退租了,这是我待的时间最长的地方,我在这间办公室待的时间比我在家里待的时间还要长···
2025年的社区办公室,吸取了上一次的教训,不租了,直接买下来了,连装修用了大概64,又是啃老本买的,交易圈啊交易圈,真的是路漫漫其修远兮···
今天上午一个以前一起做外包的朋友来电话,说准备退休了,已经捞够了,问我怎么样,我都不知道该怎么回答😂,照实说,会显得我很蠢,不照实说又没意思,支支吾吾之后,朋友也明白了,大概率我还在原地转圈····
其实这样也挺好,吃的下,睡的着,不坑不骗,不用担心“鬼上门”···



- 報酬
- いいね
- コメント
- リポスト
- 共有
2026-5-4
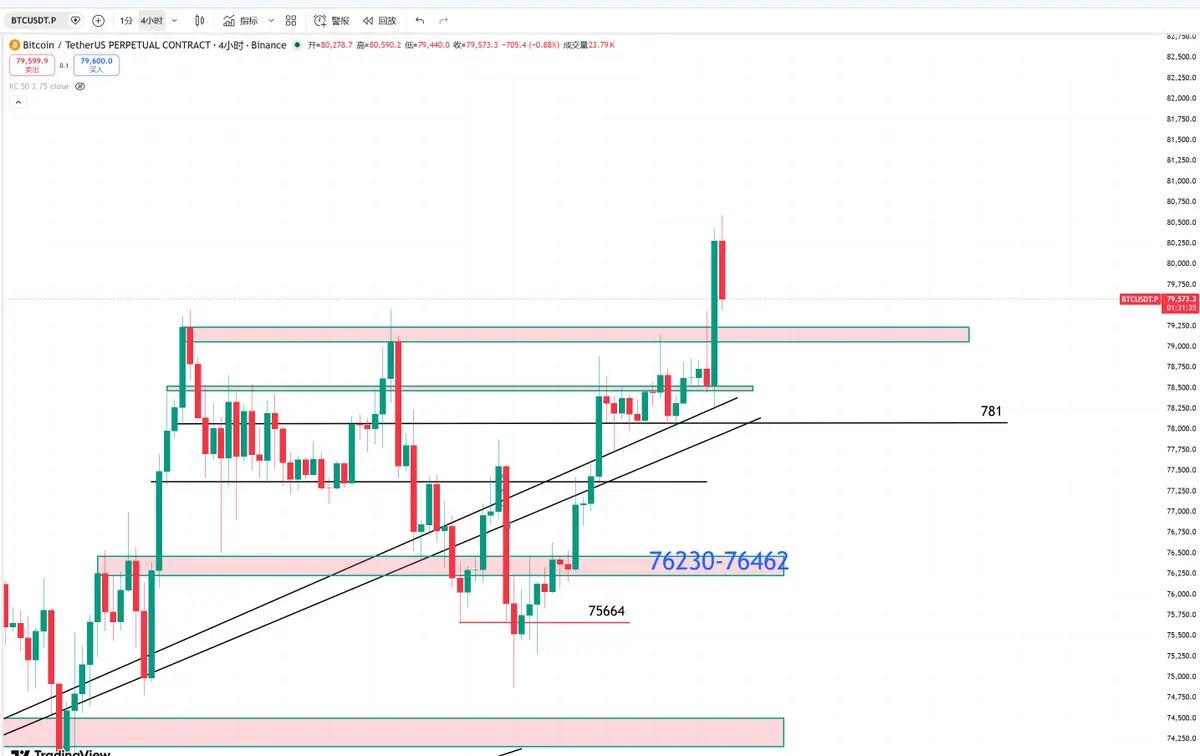
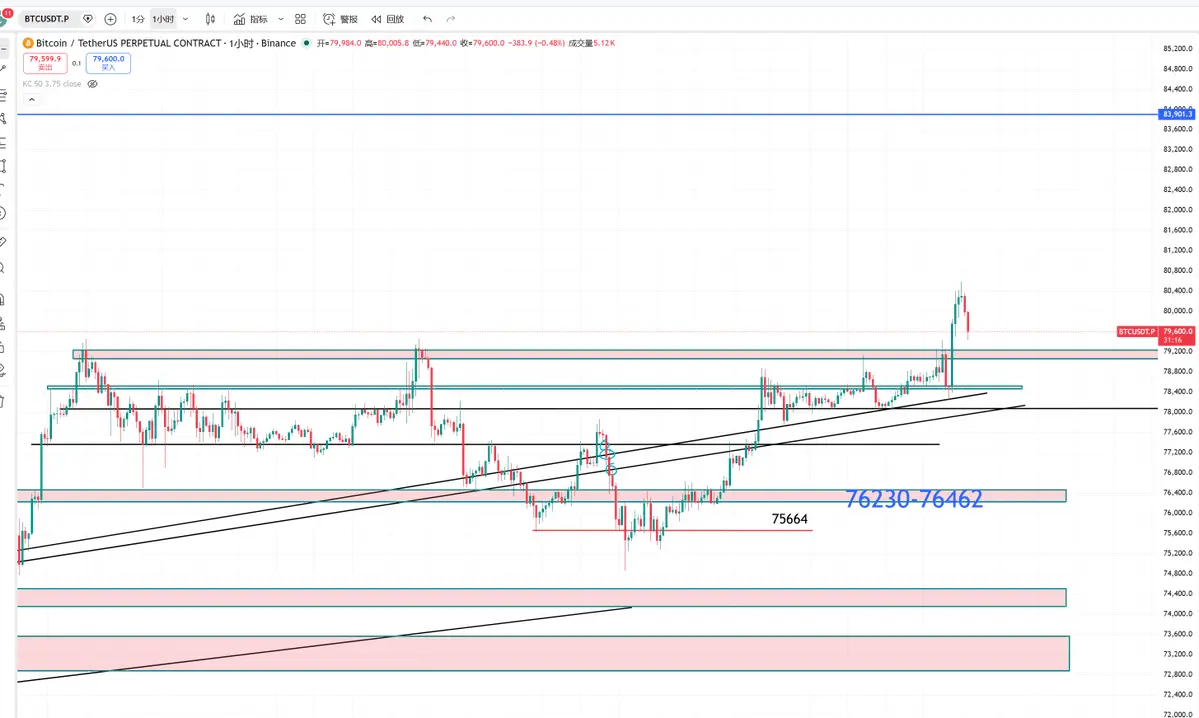
焦虑情绪を広めないこと。たとえ調整上昇でも押し目は必ずあり、空売りのポジションが適切でない場合は押し目で手仕舞い、ゆっくりと耐える。必ず耐えられる。
上昇には必ずしも好材料の予想が必要ではなく、悪材料の予想が弱まると価格は平均値に回帰しやすい。ナスダックと比較すると、追い上げ余地はまだあるが、FOMOに乗って追い上げるのは絶対に避けるべきだ。乖離が正しい位置から遠いほど、ポジションは軽くなる。多く入りすぎて死ぬのは避け、または低倍率で全力投資して死ぬのも避けるべきだ。底付近の空き筹码を逃すことは、他人の言論に左右されやすいことを意味し、価格が持続的に下落し続けることはあり得ず、楽観的な見方が続く可能性もある(これは下落初期だけで、下落が良い筹码の機会と見なされることもある)。下落が30日以上続くと、必然的に悲観的・消極的な感情になる。今の価格で全力投資し、後で4時間足や日足の調整時に自分を損切りしない可能性は低い。
また、多くの主流コインは「停滞膨張」状態にある。例えばAAVE、BNB、SOL。批判されても、いずれ追い上げが来る。TAOが37倍から235まで下落したのは、実は良い買いの機会だった。235〜242の間に買ったTAOは、今でも18%の利益がある。確実に追い上げるとしたらBNBを選ぶ。押し目があれば買い、追い上げを待つ。
ビットコインは今のところ、押し目
原文表示焦虑情绪を広めないこと。たとえ調整上昇でも押し目は必ずあり、空売りのポジションが適切でない場合は押し目で手仕舞い、ゆっくりと耐える。必ず耐えられる。
上昇には必ずしも好材料の予想が必要ではなく、悪材料の予想が弱まると価格は平均値に回帰しやすい。ナスダックと比較すると、追い上げ余地はまだあるが、FOMOに乗って追い上げるのは絶対に避けるべきだ。乖離が正しい位置から遠いほど、ポジションは軽くなる。多く入りすぎて死ぬのは避け、または低倍率で全力投資して死ぬのも避けるべきだ。底付近の空き筹码を逃すことは、他人の言論に左右されやすいことを意味し、価格が持続的に下落し続けることはあり得ず、楽観的な見方が続く可能性もある(これは下落初期だけで、下落が良い筹码の機会と見なされることもある)。下落が30日以上続くと、必然的に悲観的・消極的な感情になる。今の価格で全力投資し、後で4時間足や日足の調整時に自分を損切りしない可能性は低い。
また、多くの主流コインは「停滞膨張」状態にある。例えばAAVE、BNB、SOL。批判されても、いずれ追い上げが来る。TAOが37倍から235まで下落したのは、実は良い買いの機会だった。235〜242の間に買ったTAOは、今でも18%の利益がある。確実に追い上げるとしたらBNBを選ぶ。押し目があれば買い、追い上げを待つ。
ビットコインは今のところ、押し目
- 報酬
- いいね
- コメント
- リポスト
- 共有
本当に袁大頭…
私のは冤大頭😂
原文表示私のは冤大頭😂


- 報酬
- いいね
- コメント
- リポスト
- 共有
これはまさに、理屈を警察に求め、理屈の通らないことを裁判所に求め、狂気じみたことを記者に求めて演じきる様子を見事に描き出している😂
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
左边是新开的腾讯云的号····
右边是以前的菠萝云···
这连1个月也没😂···
右边是以前的菠萝云···
这连1个月也没😂···
- 報酬
- いいね
- コメント
- リポスト
- 共有
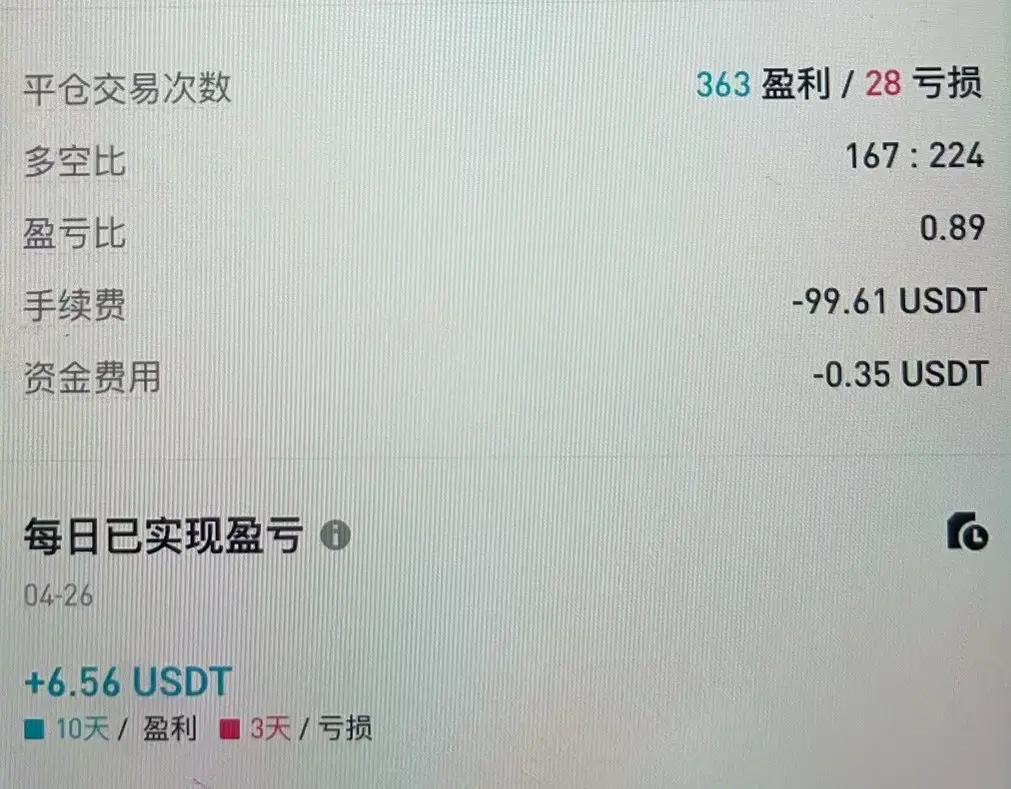
最优化アルゴリズムの後は、千日に一度の薪割りのような🔥状況はもう起きません···
ゆっくりと進めて、そのバランス点を見つけましょう
原文表示ゆっくりと進めて、そのバランス点を見つけましょう
- 報酬
- 1
- コメント
- リポスト
- 共有
ゴミ袋が空に舞う😂····
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
くそ、突風が吹いていて、ゴミ袋が24階まで吹き飛ばされた···
この良い天気も3時間も続かなかった···
原文表示この良い天気も3時間も続かなかった···

- 報酬
- いいね
- コメント
- リポスト
- 共有
今日は天気がとても良くて、窓の外を眺めてみたら、あまり不安にならなくなった···
原文表示
- 報酬
- いいね
- コメント
- リポスト
- 共有
帰曲阜から帰ったその日、小猫はすぐに「噴射戦士」になった。何を食べてお腹を壊したのか分からないが、一晩中嘔吐と下痢が続いた…
深夜🏃病院で、注射を打った後も何時になるか分からなかった…
子供の腸胃機能はまだ弱いので、生冷の食べ物や寒性の果物には注意が必要だ…
もう三日間横ばい状態になっているが、横に横たわって分析できる兄弟😂には感心する…本を書かないのは才能を埋もれさせているだけだ…
原文表示深夜🏃病院で、注射を打った後も何時になるか分からなかった…
子供の腸胃機能はまだ弱いので、生冷の食べ物や寒性の果物には注意が必要だ…
もう三日間横ばい状態になっているが、横に横たわって分析できる兄弟😂には感心する…本を書かないのは才能を埋もれさせているだけだ…



- 報酬
- いいね
- コメント
- リポスト
- 共有
観光地に建てられた全季は、環境が市街地よりも良いことが多いですが、その代償として約30%のプレミアムがつきます😂
原文表示



- 報酬
- いいね
- コメント
- リポスト
- 共有
この公演のチケットは一枚あたり100以上で、入った後五分も経たずに我慢できなくなった。残りは耐えるだけだ😂
原文表示



- 報酬
- いいね
- コメント
- リポスト
- 共有
生命は一つの輪廻であり、私が子猫の頃、父は私を連れて曲阜へ遊びに行った。九五年だったのか九四年だったのかは覚えていない。ただ、その時父はまだ小さなオペルを運転していて、济南から曲阜まで四時間以上かかったことだけは覚えている。。。その頃は六艺城と孔子の旧居だけだったが、今は六艺城のその観光スポットもなくなったようだ。。。
原文表示

- 報酬
- いいね
- コメント
- リポスト
- 共有
演出無聊主要是小妹妹跳舞跳少了,總弄些大老爺們朗誦論語和三字經,這就很無聊了。。。如果讓小妹妹跳一個小時,我覺得我也能忍得住😂
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
曲阜に着いた、朝は気づかなかったけど、今見たらツイートの中の殺気がこんなに強くなってる…
自分はただ趣味の共有だと言ってるだけで、遊びで投稿してるだけじゃないの?
原文表示自分はただ趣味の共有だと言ってるだけで、遊びで投稿してるだけじゃないの?




- 報酬
- いいね
- コメント
- リポスト
- 共有