مقدمة
في الدرس الأول، ناقشنا سبب تحول الذكاء الاصطناعي إلى البنية التحتية الجديدة لتداول العملات الرقمية. والسؤال الأهم: مهما بلغت قوة الذكاء الاصطناعي، فإنه يظل يعمل ضمن حدود البيانات التي تقدمها له.
تفشل الكثير من الاستراتيجيات ليس بسبب بساطة النموذج، بل نتيجة أخطاء اتجاهية في طبقة البيانات: إما أن جودة البيانات غير كافية، أو أن تصميم الخصائص مشوّه، أو أن طرق التحقق متحيزة.
لذلك، غالبًا ما يبدأ التداول الحقيقي المعتمد على الذكاء الاصطناعي بـ"بناء أساس البيانات" وليس بـ"اختيار النموذج". ما تزود به النموذج يحدد ما يمكنه رؤيته؛ وما يراه يحدد قدرته على إصدار الأحكام.
1. ابدأ بالإجماع: المزيد من البيانات ليس دائمًا أفضل—الأفضل هي البيانات ذات البنية السببية
يقع المتداولون الجدد في مجال الذكاء الاصطناعي كثيرًا في فخ "تجميع البيانات": جمع كل البيانات الممكنة، معتقدين أن كثرة الخصائص تسهل اكتشاف Alpha.
في الواقع، تؤدي البيانات منخفضة الجودة والمليئة بالضجيج وضعيفة الارتباط إلى تقليل استقرار النموذج. السبب بسيط:
- يتعلم النموذج "أنماطًا خاطئة" من الضجيج
- عندما تتغير بيئات التداول خارج العينة، تكون الأنماط الخاطئة أول ما ينهار
- كلما زادت الخصائص المتكررة، أصبح من الصعب شرح الاستراتيجية وصيانتها
لذا، القاعدة الأولى لبناء نظام بيانات:
اختر البيانات بناءً على مشكلات التداول—ولا تبحث عن مشكلات في البيانات نفسها.
إذا كنت تعمل على "توقع الاتجاه قصير الأجل"، ركز على البنية الدقيقة والصدمات المعنوية؛ أما في "إدارة المراكز متوسطة الأجل"، فركز أكثر على السيولة، وهيكل التقلبات، والعوامل الكلية.
2. أربعة مصادر بيانات أساسية لتداول العملات الرقمية بالذكاء الاصطناعي
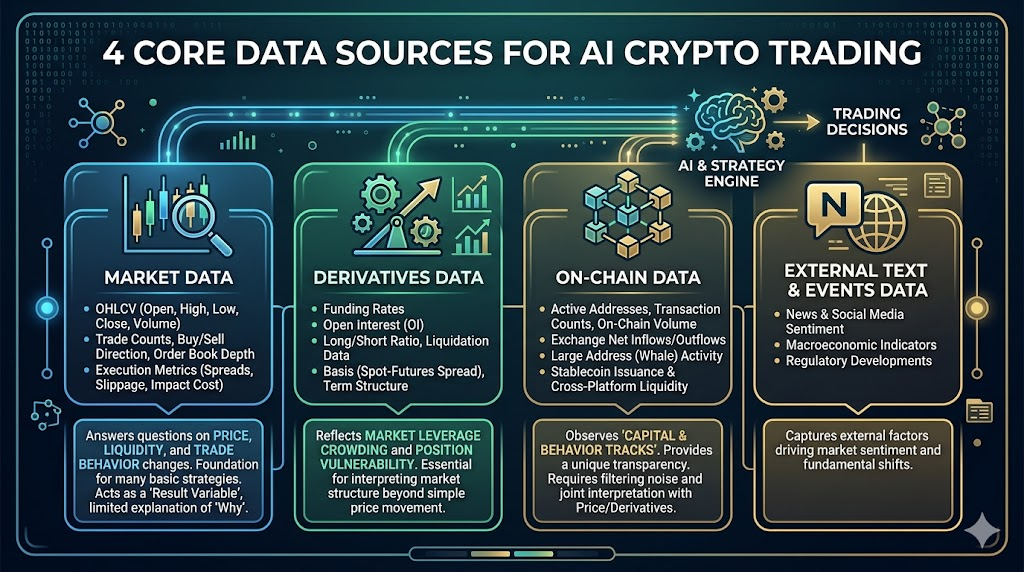
في أسواق العملات الرقمية، تأتي البيانات الأكثر قيمة عادة من أربع طبقات: بيانات السوق، بيانات المشتقات، بيانات على السلسلة، والمعلومات الخارجية.
بيانات السوق
تشكل هذه الطبقة الأساس لجميع الاستراتيجيات، وتشمل:
- OHLCV (سعر الفتح، الأعلى، الأدنى، الإغلاق، الحجم)
- عدد التداولات، اتجاه الشراء/البيع، عمق دفتر الطلبات
- الفارق السعري، الانزلاق السعري، مؤشرات تكلفة التنفيذ
تجيب هذه البيانات عن: كيف تتغير الأسعار، كيف تتغير السيولة، وكيف يتغير سلوك التداول.
يمكن بناء الكثير من الاستراتيجيات الأساسية باستخدام بيانات السوق فقط، لكن محدوديتها تكمن في أنها أشبه بـ"متغير ناتج"، مع قدرة تفسيرية محدودة على "سبب التغير".
بيانات المشتقات
ذات أهمية خاصة في أسواق العملات الرقمية، وتشمل:
- معدل التمويل
- اهتمام صريح
- نسبة حسابات الشراء/البيع، بيانات التصفية
- الأساس (فرق سعر الفوري والعقد)، هيكل الأجل
تعكس هذه البيانات ازدحام الرافعة المالية في السوق وهشاشة المراكز.
على سبيل المثال، "ارتفاع السعر + ارتفاع OI + معدل تمويل مرتفع" مقابل "ارتفاع السعر + انخفاض OI" يحمل معاني مختلفة تمامًا. الأول قد يشير إلى تقوية الاتجاه أو ازدحام الرافعة المالية؛ والثاني غالبًا ما يكون نتيجة تغطية المراكز القصيرة.
بدون بعد بيانات المشتقات، يصعب فهم بنية المراكز وراء تحركات السوق.
بيانات على السلسلة
ميزة رئيسية تميز أسواق العملات الرقمية عن الأسواق التقليدية، وتشمل:
- العناوين النشطة، عدد المعاملات، حجم التحويلات على السلسلة
- صافي التدفق/الخروج من المنصات
- سلوك العناوين الكبيرة (الحيتان)
- إصدار العملات المستقرة وتدفقاتها عبر المنصات
تكمن قيمة بيانات السلسلة في مراقبة "مسارات رأس المال والسلوك"، لكن التحدي يكمن في تأخر التفسير وتصفيه الضجيج.
على سبيل المثال، زيادة التدفق إلى المنصات قد تعني الاستعداد للبيع أو التحوط. يجب تفسير بيانات السلسلة مع هيكل السعر وبيانات المشتقات—واستخدامها منفردة قد يؤدي بسهولة إلى سوء التقدير.
البيانات النصية والحدثية الخارجية (الأخبار/السوشيال/العوامل الكلية)
تشمل الأخبار، حرارة النقاش على وسائل التواصل الاجتماعي، الأحداث السياسية، توقيتات إصدار البيانات الكلية.
هذه البيانات بمثابة "مصدر الصدمات": تفسر لماذا ترتفع التقلبات فجأة أو تتغير الاتجاهات لفترة وجيزة.
لكن لهذا النوع من البيانات مشكلات واضحة: ذاتية عالية، مليئة بالضجيج، مختلطة بين الصحيح والخاطئ.
لذا، من الأفضل استخدام النصوص الخارجية كـ"عوامل تنبيه للمخاطر" و"مرشحات للأحداث"، ولا يُنصح بالاعتماد عليها كإشارات دخول رئيسية.
3. من البيانات الخام إلى الخصائص القابلة للتداول: هندسة الخصائص هي الفاصل الحقيقي للاستراتيجيات
الذكاء الاصطناعي لا يفهم "سرديات السوق" بشكل مباشر؛ بل يتعرف فقط على أنماط الخصائص.
لذا، الخطوة التالية ليست الإسراع في تدريب النماذج بل تحويل البيانات الخام إلى خصائص قابلة للتعلم والتحقق والتداول.
يمكن تصنيف الخصائص المفيدة الشائعة إلى أربع مجموعات:
- خصائص الاتجاه: الزخم، ميل المتوسط المتحرك، قوة الاختراق
- خصائص التقلب: التقلب التاريخي، مدى النطاق، قفزات التقلب
- خصائص هيكلية: انحراف معدل التمويل، معدل تغير OI، تغير الأساس
- خصائص سلوكية: تغير صافي التدفق على السلسلة، صدمات معنويات الأخبار، ارتفاع حرارة السوشيال بشكل غير طبيعي
المفتاح ليس في "الخصائص المبهرجة"، بل في ثلاثة معايير:
- هل لها معنى اقتصادي (وليس مجرد تركيب رياضي)
- هل يمكن الحصول عليها في نقاط زمنية فعلية (دون معلومات مستقبلية)
- هل يمكن أن تستمر عبر مراحل السوق المختلفة (صاعد/هابط/تجميعي دون تشوه مفرط)
4. تصميم العلامات: ما تطلب من النموذج توقعه يحدد ما يتعلمه
يفترض الكثيرون تلقائيًا أن النموذج يجب أن يتنبأ بـ"اتجاه الشمعة التالية صعودًا أو هبوطًا"، لكن ذلك ليس بالضرورة الأمثل.
يمكن أن تتخذ أهداف التداول أشكال علامات متنوعة:
- علامات تصنيف: ما إذا كانت عوائد الفترات n المستقبلية تتجاوز حدًا معينًا
- علامات انحدار: عوائد الفترات n المستقبلية
- علامات مخاطر: ما إذا كان هناك انسحاب كبير في الفترات n المستقبلية
- علامات هيكلية: ما إذا كان التقلب يتوسع أو معدل التمويل يصبح متطرفًا في المستقبل
إذا كان هدف استراتيجيتك "تجنب الانسحابات الكبيرة" لكنك تستخدم "اتجاه السعر قصير الأجل" كعلامة، فلن يكون النموذج مفيدًا مهما بلغت دقته.
لذا يجب أن تتطابق العلامات مع أهداف الاستراتيجية: أي ربح تسعى إليه في التداول، اجعل النموذج يتعلم ذلك الهدف.
5. مفتاح تحقق البيانات: في عالم السلاسل الزمنية، طرق التحقق أهم من النماذج
في مهام التعلم الآلي التقليدية، من الشائع خلط مجموعات التدريب والاختبار عشوائيًا؛ لكن في التداول يؤدي ذلك إلى تشويه كبير.
لأن الأسواق لها بنية تعتمد على الزمن—يجب ألا "يتسرب" أي معلومات مستقبلية إلى الماضي.
يجب أن يلتزم التداول بالذكاء الاصطناعي بثلاث قواعد تحقق على الأقل:
- تقسيم التدريب/التحقق/الاختبار حسب الزمن—وليس بالخلط العشوائي
- يجب أن يغطي التحقق خارج العينة بيئات تقلب مختلفة
- استخدم نافذة متدحرجة (اختبار متقدم) لمحاكاة النشر الفعلي
تنهار العديد من "استراتيجيات المعجزة في الاختبار الرجعي" ليس لأن الأسواق ساءت، بل لأن طرق الاختبار كانت متفائلة منذ البداية.
6. خمسة أخطاء شائعة في البيانات
انحياز التطلع للمستقبل
استخدام بيانات غير متاحة في وقتها يؤدي إلى نتائج مبالغ فيها.
انحياز البقاء
التدريب فقط على العملات أو المنصات الباقية—وتجاهل العينات الفاشلة.
الإفراط في التنظيف
حذف الضجيج الحقيقي باعتباره بيانات غير نظيفة—فيخسر النموذج القدرة على التكيف مع الأسواق المتطرفة.
تسرب الخصائص
تحتوي الخصائص ضمنيًا على معلومات العلامة—مما يجعل النموذج يبدو أكثر دقة من الواقع.
عدم تطابق التردد
فرض خصائص على السلسلة منخفضة التردد في مهام التداول عالي التردد—مما يسبب إشارات خاطئة.
هذه المشكلات لا تظهر أثناء الاختبار الرجعي، لكنها تتضخم بسرعة في التداول المباشر.
سير عمل بيانات عملي: ابدأ صغيرًا ومستقرًا ثم توسع
بالنسبة لمتعلمي الدورة، النهج الأكثر أمانًا ليس البدء بـ"نموذج شامل لجميع العوامل في السوق"، بل البدء بإطار بيانات أولي قابل للتطبيق:
- اختر أصلًا واحدًا (مثل BTC أو ETH)
- ابدأ بأنواع بيانات السوق + المشتقات
- ابنِ 10–20 خاصية أساسية ذات معنى اقتصادي
- صمّم علامة واضحة (مثال: هل عائد الأربع ساعات القادمة >0)
- تحقق زمني + اختبار متدحرج
- أضف تدريجيًا عوامل السلسلة والنصوص
هذا النهج يحافظ على وضوح تحديد المشكلات، ويقلل من تكاليف التكرار، ويقصر مسار النشر.
لا تُبنى الأنظمة المعقدة دفعة واحدة—بل تتوسع طبقة تلو طبقة من أنظمة صغيرة قابلة للتفسير.
الأهمية الفعلية لـ Gate for AI في طبقة البيانات
في التطبيق العملي، غالبًا ما تكون مرحلة البيانات هي الأكثر استهلاكًا للوقت: جمع متعدد المصادر، تنظيف الصيغ، محاذاة الزمن، خطوط معالجة الخصائص، ودمج الاستراتيجيات.
لهذا السبب تزداد أهمية أدوات الذكاء الاصطناعي القائمة على المنصات. وبالاستعانة بـ Gate for AI كمثال على هذه البنية التحتية—تكمن القيمة في مساعدة المتداولين على إكمال دورة الهندسة من البيانات إلى الاستراتيجية بكفاءة وتقليل الاحتكاك بين البحث والتنفيذ، وليس في "توليد استراتيجية عالمية". يظل على المتداولين تحديد المشكلات، وتعيين القيود، وإدارة المخاطر—لكن سير العمل الأساسي يمكن أن يكون أكثر معيارية وقابلية لإعادة الاستخدام.





