比特国王归来
‼️ guan和平 轮老铁们给U‼️ 6号合约/现货单已更新👇币圈只跟对的人,感谢大家支持,春节半价优惠订阅已超400人💰苹果点👇
https://www.gate.com/zh/profile/比特国王归来
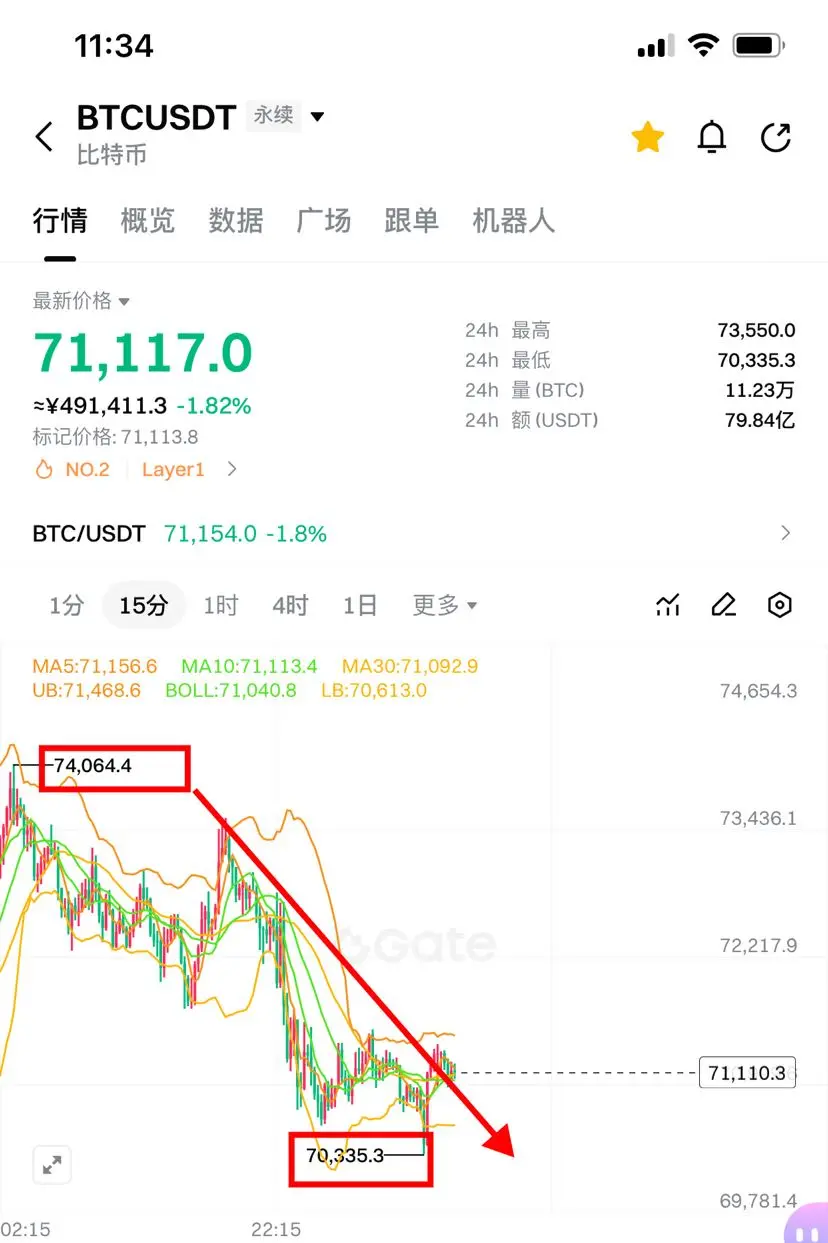
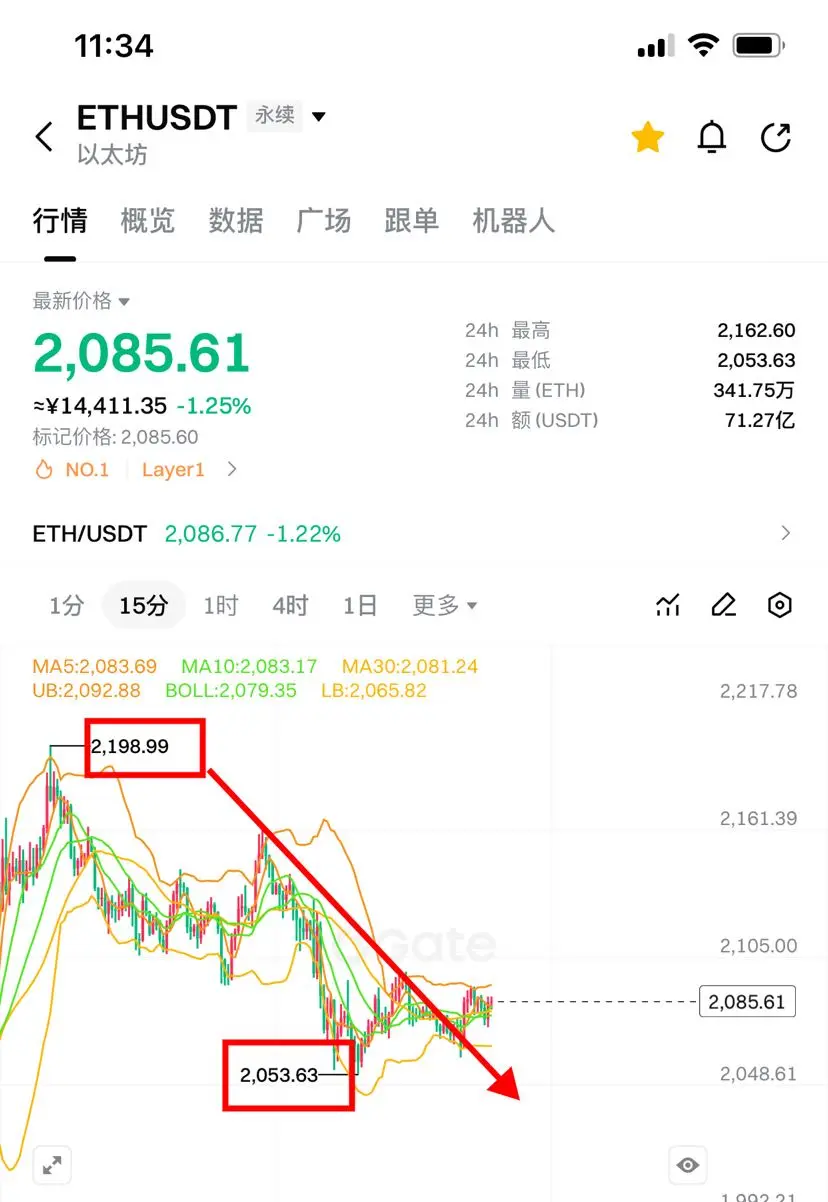
🔥近期连吃360余万u‼️上周五70000/2150空62950/1835吃85万📉周六反手63000/1840多74600/2200吃80万📈周二1925/65300多2200/74600再吃45万📈反手74000/2195空现70100/2055再吃大肉
#加密市场小幅下跌
https://www.gate.com/zh/profile/比特国王归来
🔥近期连吃360余万u‼️上周五70000/2150空62950/1835吃85万📉周六反手63000/1840多74600/2200吃80万📈周二1925/65300多2200/74600再吃45万📈反手74000/2195空现70100/2055再吃大肉
#加密市场小幅下跌

- 赞赏
- 12
- 10
- 转发
- 分享
大大大大大泡泡糖 :
:
吉祥如意 🧧查看更多
美伊紧张局势再次在全球金融市场引发不确定性。每当地缘政治风险升级,投资者倾向于将资金从风险较高的资产转向更安全的资产。这一转变已经开始影响股票、商品和加密货币市场。
能源市场对中东局势尤为敏感,因为该地区在全球石油供应中扮演着关键角色。任何对生产或运输路线的威胁都可能迅速推高油价。如果紧张局势持续升级,布伦特和WTI原油可能会进一步上涨,可能会给全球通胀带来压力。
黄金和白银等避险资产也受到更多关注。历史上,在地缘政治不确定时期,投资者会增加对贵金属的配置,以对冲波动和经济不稳定。因此,这些资产的需求正在增强。
加密货币市场的反应则更为复杂。一方面,一些投资者将数字资产视为对冲传统金融风险的替代品;另一方面,如果全球市场的恐惧情绪加剧,交易者可能会减少对高波动性资产如加密货币的敞口,以保持流动性。这种动态可能导致短期内波动性增加。
归根结底,市场走向很大程度上取决于外交发展的进展。如果通过谈判缓解紧张局势,风险资产可能会反弹;但如果冲突升级,市场可能会经历更高的波动性、更强的能源价格,以及对避险资产的持续需求。
#地缘政治
#全球市场
#油价
查看原文能源市场对中东局势尤为敏感,因为该地区在全球石油供应中扮演着关键角色。任何对生产或运输路线的威胁都可能迅速推高油价。如果紧张局势持续升级,布伦特和WTI原油可能会进一步上涨,可能会给全球通胀带来压力。
黄金和白银等避险资产也受到更多关注。历史上,在地缘政治不确定时期,投资者会增加对贵金属的配置,以对冲波动和经济不稳定。因此,这些资产的需求正在增强。
加密货币市场的反应则更为复杂。一方面,一些投资者将数字资产视为对冲传统金融风险的替代品;另一方面,如果全球市场的恐惧情绪加剧,交易者可能会减少对高波动性资产如加密货币的敞口,以保持流动性。这种动态可能导致短期内波动性增加。
归根结底,市场走向很大程度上取决于外交发展的进展。如果通过谈判缓解紧张局势,风险资产可能会反弹;但如果冲突升级,市场可能会经历更高的波动性、更强的能源价格,以及对避险资产的持续需求。
#地缘政治
#全球市场
#油价


- 赞赏
- 7
- 4
- 转发
- 分享
KatyPaty :
:
直达月球 🌕查看更多
3.6午间大饼以太思路解析!
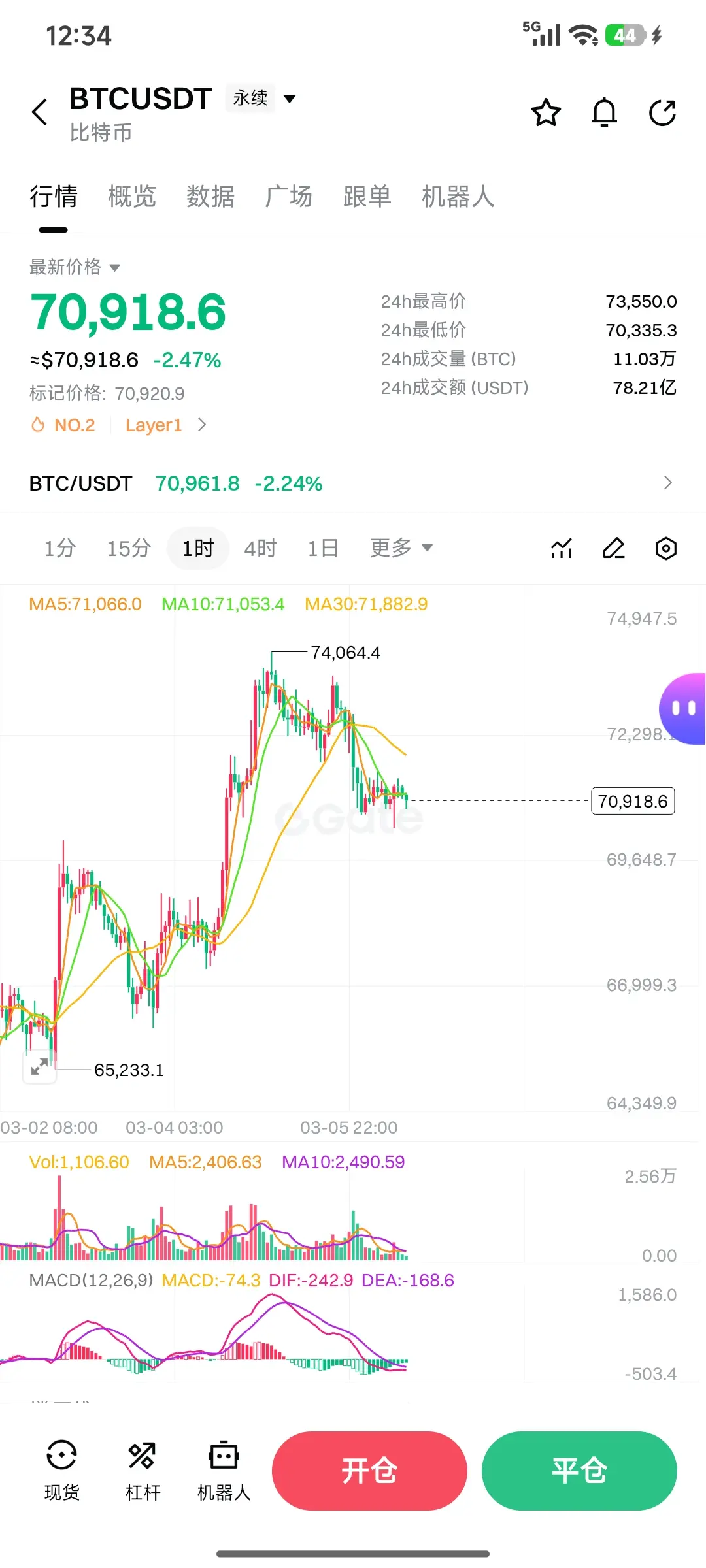
先看大饼:
小时级别刚跌破了一个看跌旗形,回踩了之前的高点70117附近,现在确认支撑有效,正在走反弹。下方那两根像针一样插下去的K线,能不能形成“双针探底”还不好说,想让这个形态成立,必须得创出比之前更高的高点才行。
现在大饼上方最关键的阻力位,就是71623这个颈线位。如果能放量突破这里,就会出现更高的高点,双针探底形态自然成立,行情就能重新回到旗形内部运行,顺势摸一下72731的阻力位,甚至去挑战前高或者创出新高。反之,如果上不去71623,那这波反弹也就到头了,不用再往上看。
下方的多头趋势线也很关键,对应价格在7万附近。只要这条线不被跌破,大饼就不会出现深度回踩;一旦跌破7万,回调就正式开始。
所以今天重点盯两个位置:上方71623不突破涨不起来,下方7万不跌破跌不下去,上不去下不来就会在71626-70000区间盘整。操作上,带量突破71623可以右侧追多,带量跌破70562且反抽收不回就右侧追空,记得带好止损。
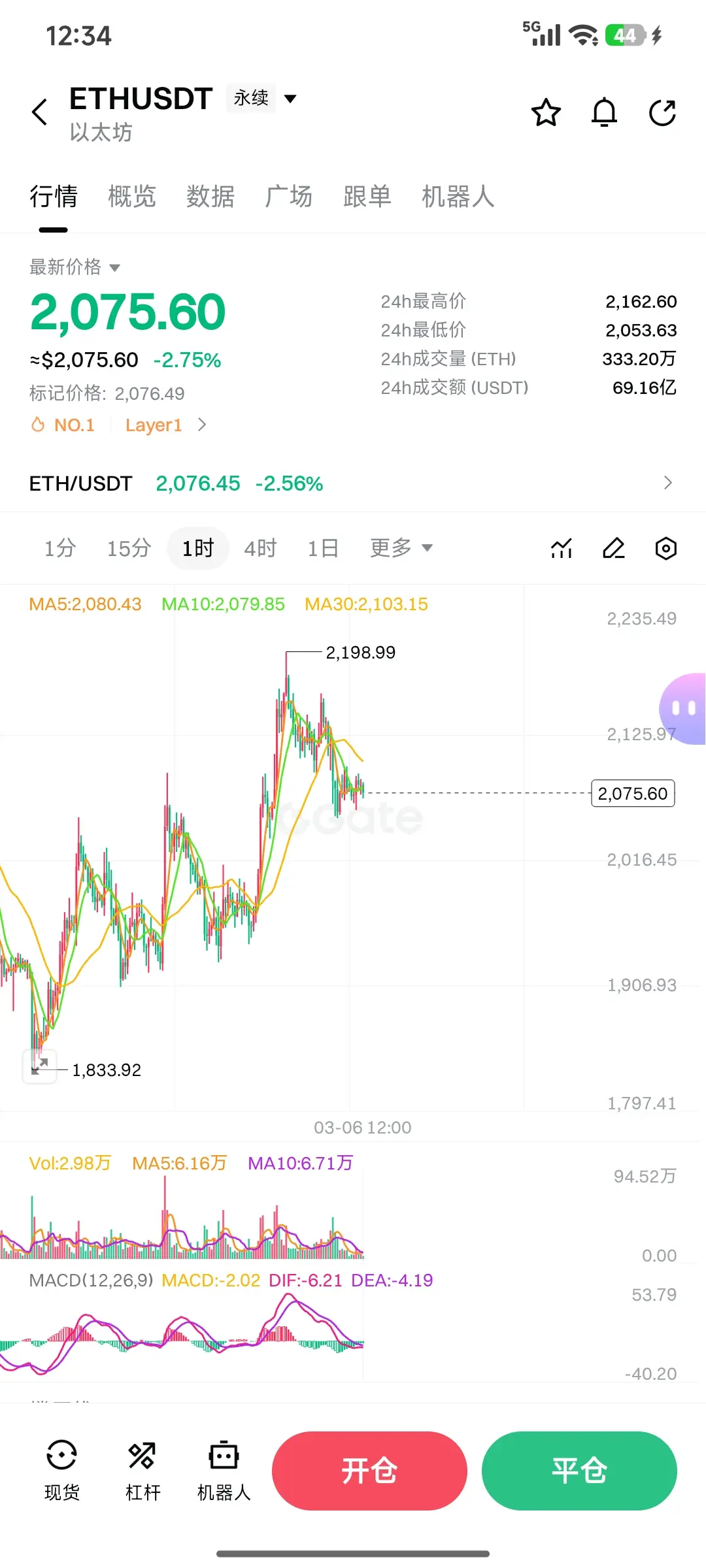
再看以太:
它刚跌破了一个三角形,现在三角形的下边界就成了阻力位。如果能重新回到三角形内部,就可以向上看之前的高点;收不回去,就别指望涨了。如果跌破下方2055的支撑,这波上涨就结束,只能向下看1985。
操作上,以太带量突破2094可以右侧追多,带好止损;2059带量跌破就右侧追空。回踩2001确认支撑有效可以多一手,跌破196
先看大饼:
小时级别刚跌破了一个看跌旗形,回踩了之前的高点70117附近,现在确认支撑有效,正在走反弹。下方那两根像针一样插下去的K线,能不能形成“双针探底”还不好说,想让这个形态成立,必须得创出比之前更高的高点才行。
现在大饼上方最关键的阻力位,就是71623这个颈线位。如果能放量突破这里,就会出现更高的高点,双针探底形态自然成立,行情就能重新回到旗形内部运行,顺势摸一下72731的阻力位,甚至去挑战前高或者创出新高。反之,如果上不去71623,那这波反弹也就到头了,不用再往上看。
下方的多头趋势线也很关键,对应价格在7万附近。只要这条线不被跌破,大饼就不会出现深度回踩;一旦跌破7万,回调就正式开始。
所以今天重点盯两个位置:上方71623不突破涨不起来,下方7万不跌破跌不下去,上不去下不来就会在71626-70000区间盘整。操作上,带量突破71623可以右侧追多,带量跌破70562且反抽收不回就右侧追空,记得带好止损。
再看以太:
它刚跌破了一个三角形,现在三角形的下边界就成了阻力位。如果能重新回到三角形内部,就可以向上看之前的高点;收不回去,就别指望涨了。如果跌破下方2055的支撑,这波上涨就结束,只能向下看1985。
操作上,以太带量突破2094可以右侧追多,带好止损;2059带量跌破就右侧追空。回踩2001确认支撑有效可以多一手,跌破196
- 赞赏
- 2
- 评论
- 转发
- 分享
芝麻开门
芝麻开门
创建人@梦想旅途
上市进度
100.00%
市值:
$2084.17
更多代币

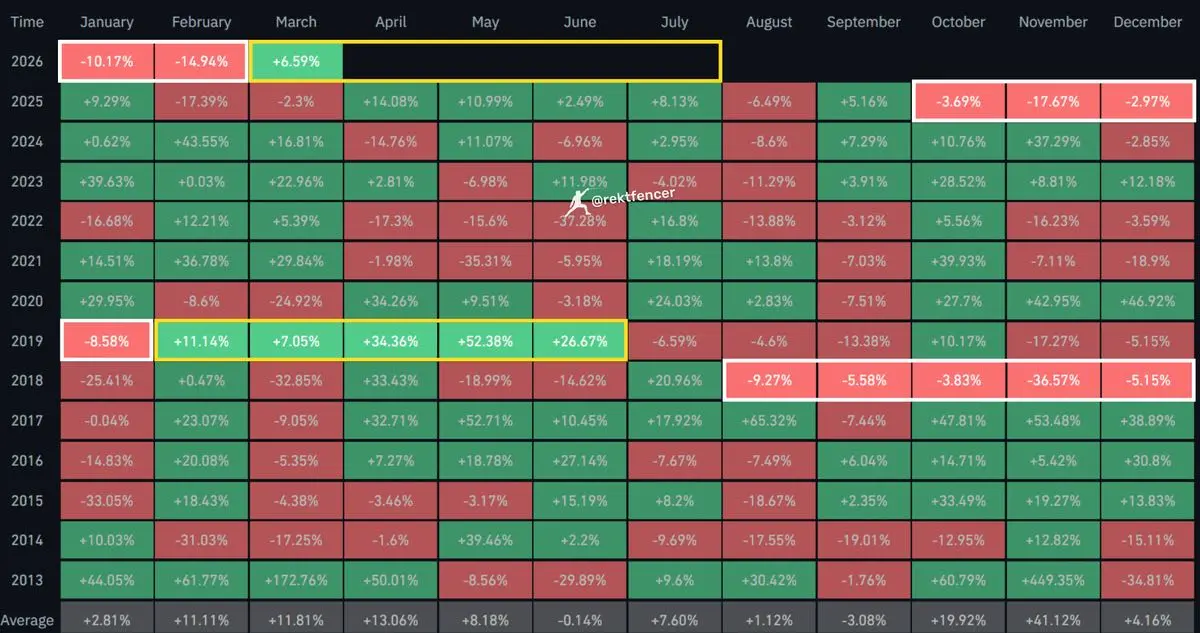
这种模式将创造新的百万富翁
上次$BTC 连续关闭了5个红色月线蜡烛
它连续5个月累计上涨了310%
而我们现在只是第一个月
更高#GateLaunchesGateforAI #CryptoMarketsDipSlightly $BTC
上次$BTC 连续关闭了5个红色月线蜡烛
它连续5个月累计上涨了310%
而我们现在只是第一个月
更高#GateLaunchesGateforAI #CryptoMarketsDipSlightly $BTC
BTC-2.46%
- 赞赏
- 点赞
- 评论
- 转发
- 分享
今天是星期五。我在等待低成交量,并预期加密货币市场的波动性会较低。仍在等待下周。
查看原文

- 赞赏
- 1
- 1
- 转发
- 分享
Lions_Lionish :
:
独家最新币种与市场动态,尽在GATE SQUARE ✅ 立即关注我 🔥💰💵
- 赞赏
- 2
- 评论
- 转发
- 分享
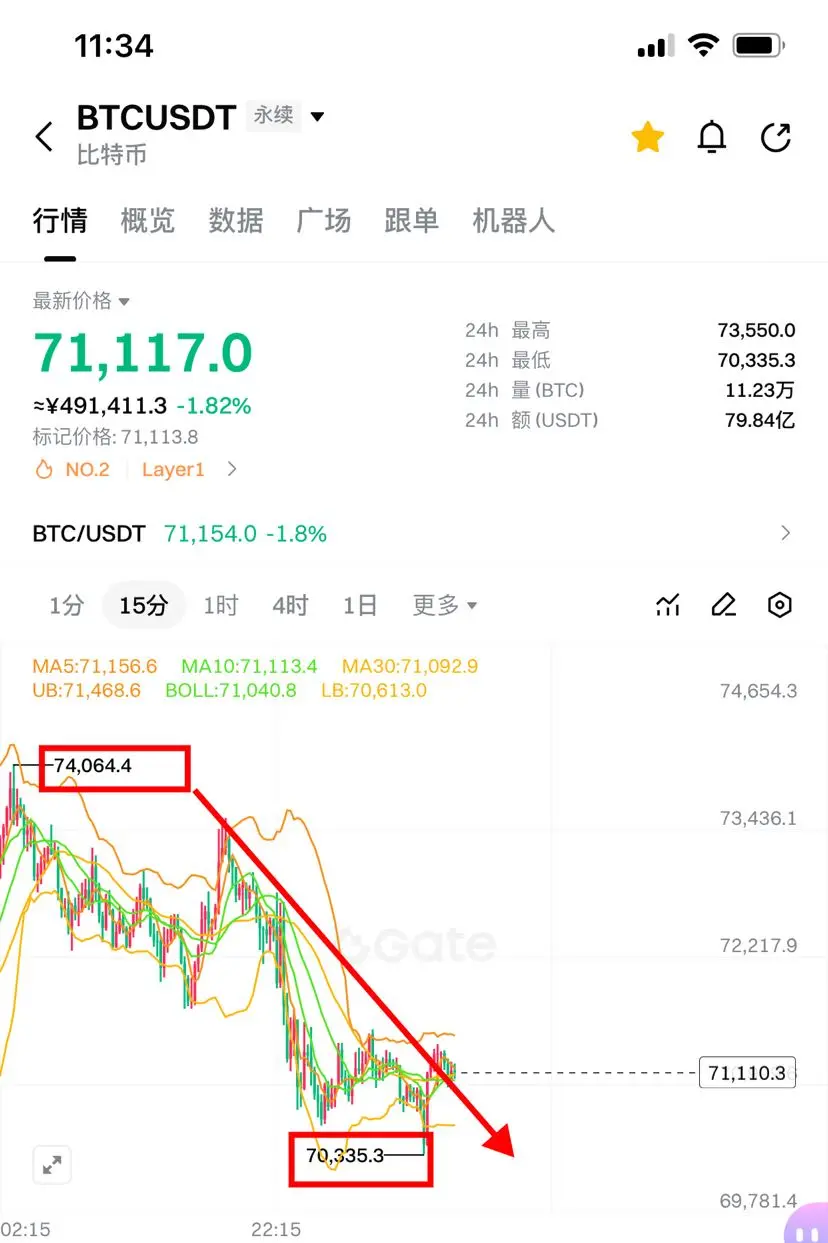
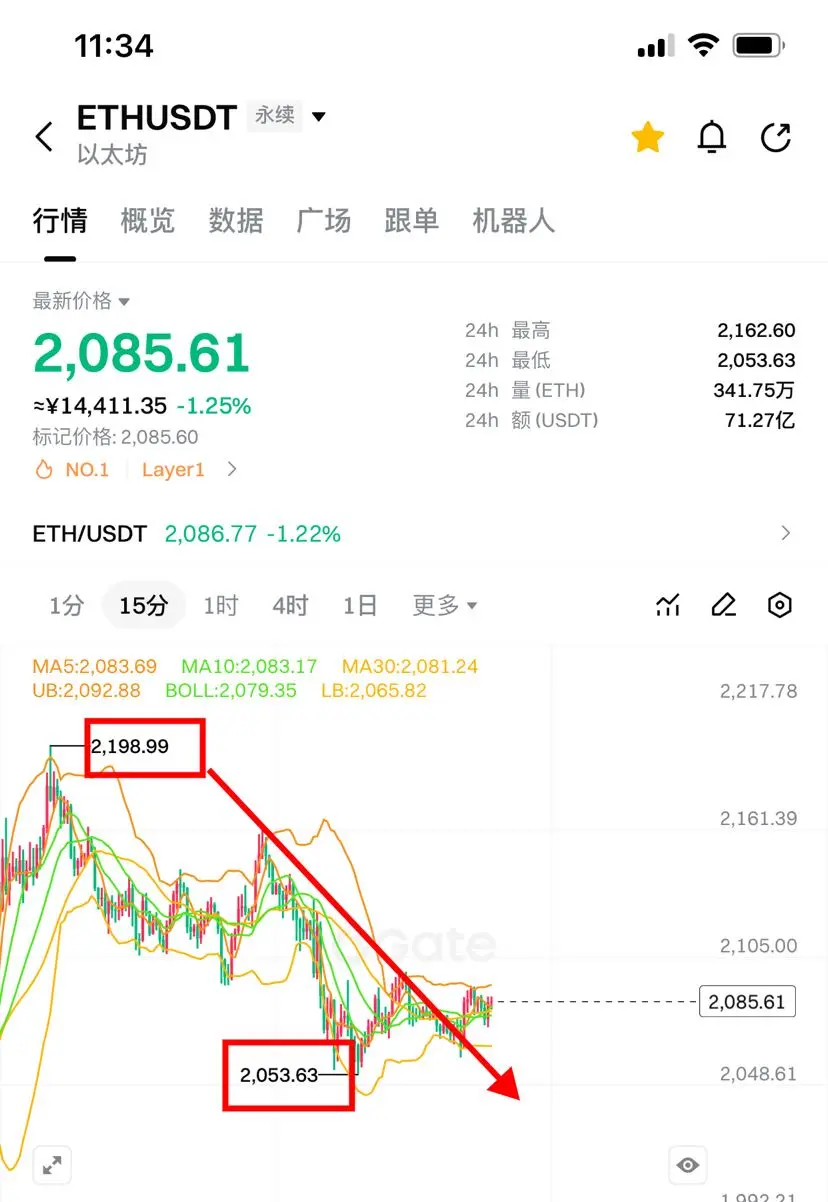
‼️第一单👇
‼️方向:空(cpi利多,求稳挂第二位)
==============
72400附近-72700附近,损74100
2120附近-2140附近,损2190
盈:71000//69500//68000
盈:2110//2050//1980
=============
75300附近-75600附近,损77000
2225附近-2245附近,损2295
#GateforAI重磅上线
‼️方向:空(cpi利多,求稳挂第二位)
==============
72400附近-72700附近,损74100
2120附近-2140附近,损2190
盈:71000//69500//68000
盈:2110//2050//1980
=============
75300附近-75600附近,损77000
2225附近-2245附近,损2295
#GateforAI重磅上线

- 赞赏
- 2
- 评论
- 转发
- 分享
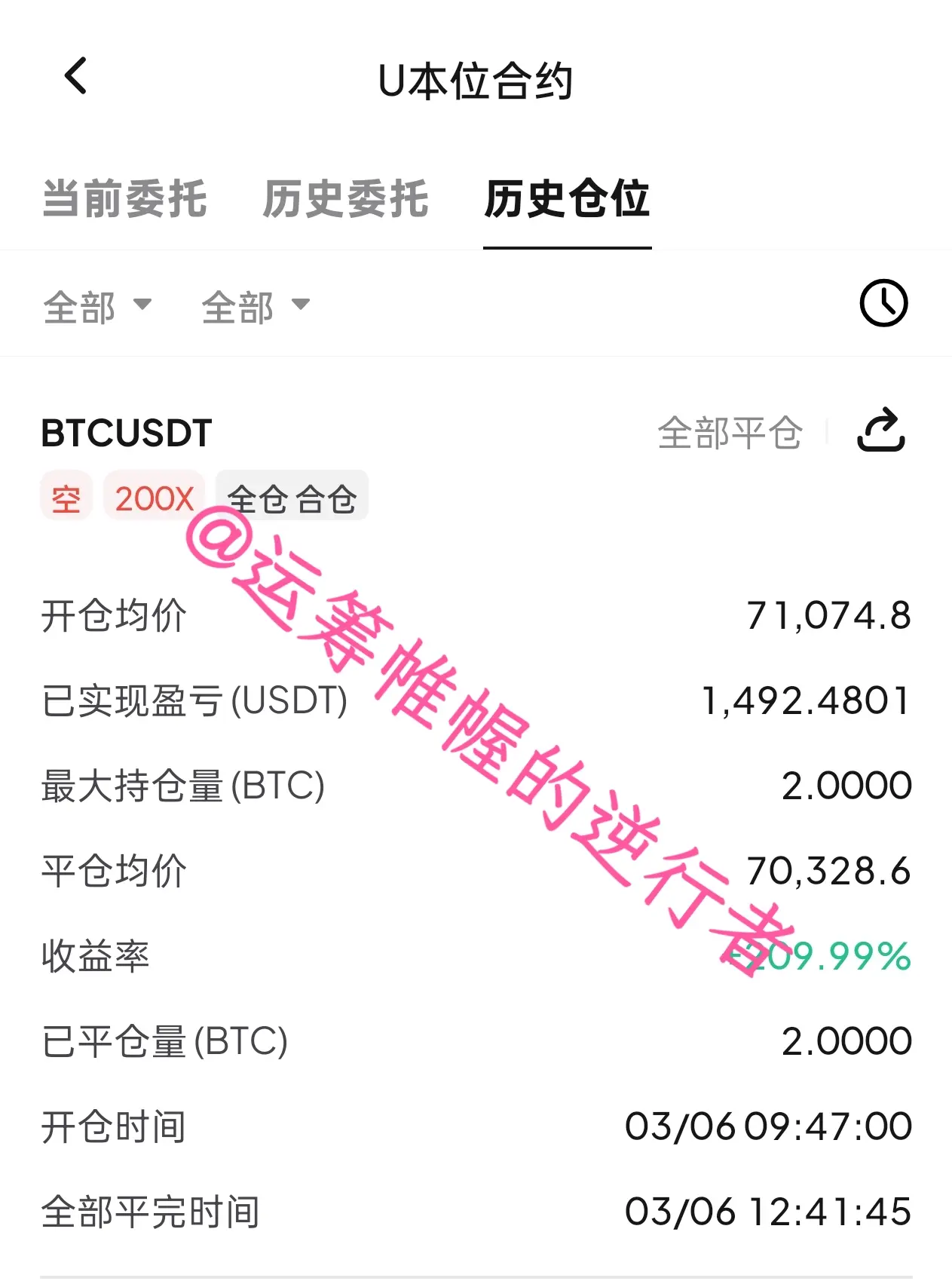
市场小跌别慌:币圈这点波动连热身都算不上
今天的加密市场出现了一点点回调。
很多人看到K线变绿,就开始怀疑行情是不是要结束。
但如果你在币圈待过一段时间,就会知道一个残酷事实:
这点波动,连热身都算不上。
加密市场的波动率,本来就比传统金融高很多。
在股票市场,2%的波动可能会登上新闻。
但在币圈,5%都只是“正常工作日”。
这也是为什么很多传统投资者进入加密市场后会有一种感觉:
心脏被强行升级了。
因为你每天都在经历 情绪过山车。
其实市场小幅回调背后的逻辑很简单:
涨多了,自然会有人兑现利润。
尤其是在短线资金占比较高的市场。
这些资金没有信仰,也不关心技术。
他们只关心一件事:
今天赚了多少。
于是当价格上涨后,他们就会开始止盈。
市场自然就会回落。
但真正的关键在于:
长期资金是否还在。
只要长期资金还在,市场的结构就不会轻易改变。
而历史经验告诉我们:
真正的大行情,往往不是一路狂飙。
而是震荡上行。
很多人总以为牛市应该是每天上涨。
但真实的牛市其实更像这样:
涨 震荡 回调 再涨
不断循环。
如果你把时间周期拉长,就会发现很多回调其实只是K线里的小波纹。
所以面对这种市场波动,最重要的是保持一个清醒认知:
波动不是风险。
真正的风险是:
在恐慌中卖出 在狂热中买入
这才是大多数亏钱的原因。
市场永远在筛选两种人:
没有耐心的人 没有纪律的人
而能留下来的,往往不是最聪
今天的加密市场出现了一点点回调。
很多人看到K线变绿,就开始怀疑行情是不是要结束。
但如果你在币圈待过一段时间,就会知道一个残酷事实:
这点波动,连热身都算不上。
加密市场的波动率,本来就比传统金融高很多。
在股票市场,2%的波动可能会登上新闻。
但在币圈,5%都只是“正常工作日”。
这也是为什么很多传统投资者进入加密市场后会有一种感觉:
心脏被强行升级了。
因为你每天都在经历 情绪过山车。
其实市场小幅回调背后的逻辑很简单:
涨多了,自然会有人兑现利润。
尤其是在短线资金占比较高的市场。
这些资金没有信仰,也不关心技术。
他们只关心一件事:
今天赚了多少。
于是当价格上涨后,他们就会开始止盈。
市场自然就会回落。
但真正的关键在于:
长期资金是否还在。
只要长期资金还在,市场的结构就不会轻易改变。
而历史经验告诉我们:
真正的大行情,往往不是一路狂飙。
而是震荡上行。
很多人总以为牛市应该是每天上涨。
但真实的牛市其实更像这样:
涨 震荡 回调 再涨
不断循环。
如果你把时间周期拉长,就会发现很多回调其实只是K线里的小波纹。
所以面对这种市场波动,最重要的是保持一个清醒认知:
波动不是风险。
真正的风险是:
在恐慌中卖出 在狂热中买入
这才是大多数亏钱的原因。
市场永远在筛选两种人:
没有耐心的人 没有纪律的人
而能留下来的,往往不是最聪


【当前用户分享了他的交易卡片,若想了解更多优质交易信息,请到 App 端查看】
- 赞赏
- 5
- 4
- 转发
- 分享
KatyPaty:
直达月球 🌕查看更多
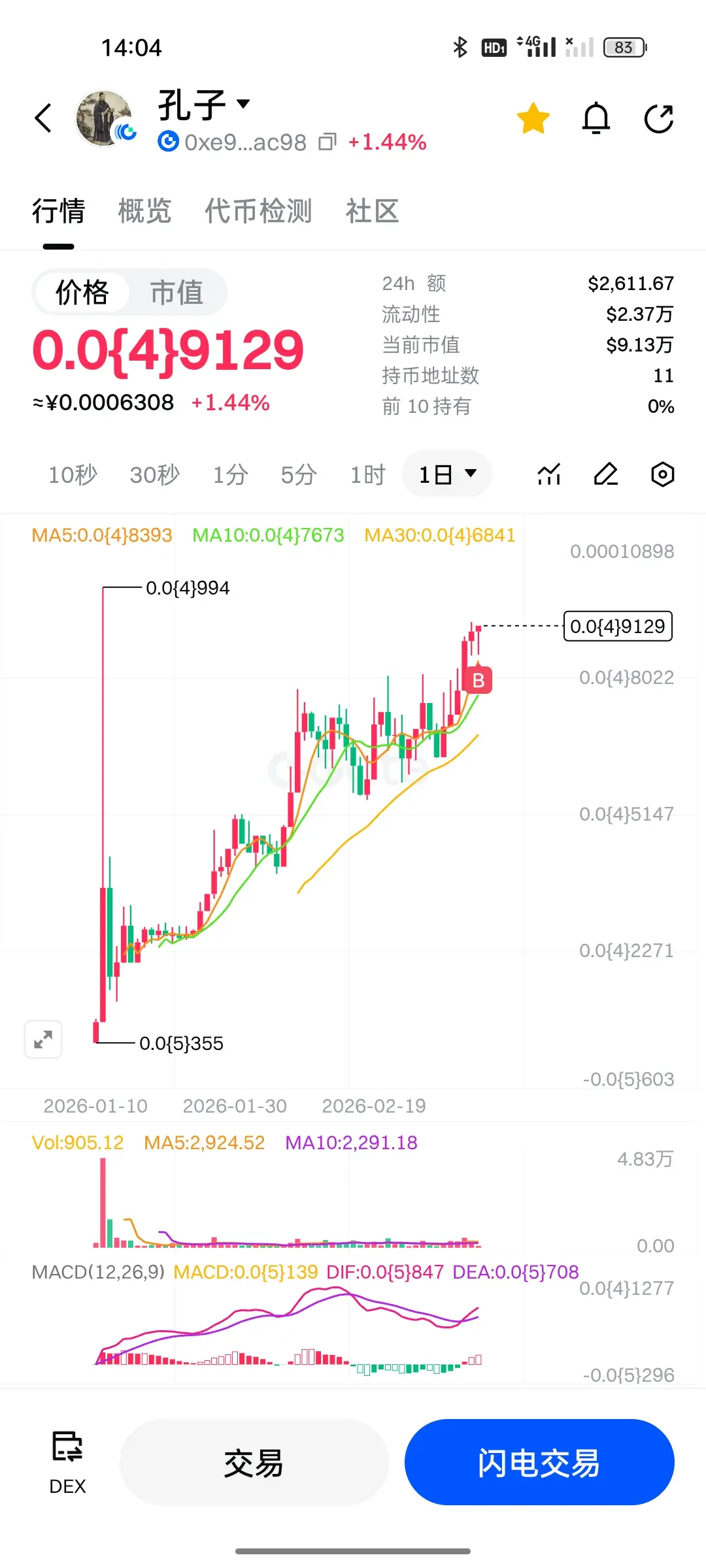
SJZ
三角洲
创建人@激进打法运神
上市进度
0.00%
市值:
$0.1
更多代币
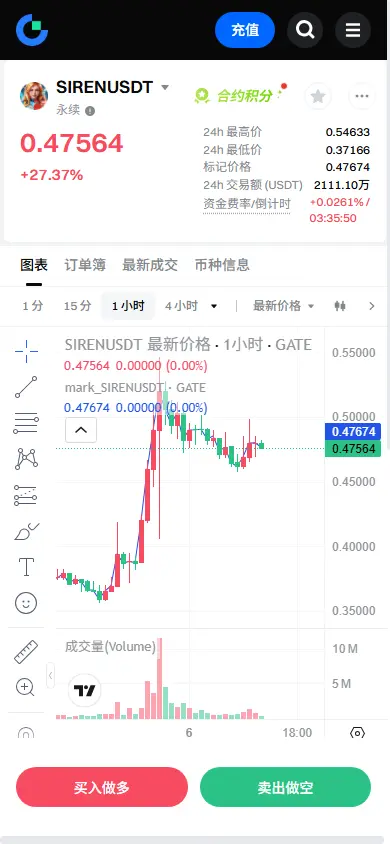
#GateforAI重磅上线 $SIREN 1H级别在经历巨幅拉升后,正进行健康的回踩整理,价格在1小时EMA20均线附近获得支撑,动能正在修复。4小时级别看,价格仍处于EMA20强趋势线上方,整体上升结构未破坏。当前盘口卖压集中在0.477上方,但买盘深度在下方0.476区域厚实,显示有资金在关键位置护盘。持仓量保持稳定,未因价格回调而大幅流出,表明主力并未离场。1小时RSI已从超买区回落至健康区域,为再次上攻蓄力。
🎯方向:做多
⚡入场/挂单:0.457 - 0.468
🛑止损:0.440
🚀目标1:0.500
🚀目标2:0.525
🛡️交易管理:
- 执行策略:价格到达目标1后,减仓50%锁定利润,并将剩余仓位的止损上移至入场价。若价格强势突破0.525,可将止损上移至0.500,博取更大空间。
(深度逻辑:过去24小时涨幅近30%,属于典型的热币行情。1小时K线在凌晨放量拉升后,目前缩量回踩至1小时EMA20均线及4小时EMA50均线双重支撑区域,这是经典的强势回调买点。盘口数据显示,虽然当前为小额卖单主导,但下方买单堆积明显,存在护盘迹象。结合持仓量稳定和正资金费率,市场情绪偏多,回踩即是机会。)
#我在Gate广场过新年
🎯方向:做多
⚡入场/挂单:0.457 - 0.468
🛑止损:0.440
🚀目标1:0.500
🚀目标2:0.525
🛡️交易管理:
- 执行策略:价格到达目标1后,减仓50%锁定利润,并将剩余仓位的止损上移至入场价。若价格强势突破0.525,可将止损上移至0.500,博取更大空间。
(深度逻辑:过去24小时涨幅近30%,属于典型的热币行情。1小时K线在凌晨放量拉升后,目前缩量回踩至1小时EMA20均线及4小时EMA50均线双重支撑区域,这是经典的强势回调买点。盘口数据显示,虽然当前为小额卖单主导,但下方买单堆积明显,存在护盘迹象。结合持仓量稳定和正资金费率,市场情绪偏多,回踩即是机会。)
#我在Gate广场过新年
SIREN22.98%
- 赞赏
- 2
- 评论
- 转发
- 分享
#加密市场小幅下跌 中东地缘紧张缓解,暂时对币圈应该不会有什么太大影响,不过还是要继续时刻关注后续的事态发展。今天的重点是关注晚间的非农数据,本周公布的ADP及初请等数据是利空币价的,那么晚间非农数据很可能将好于预期,那将意味着美联储3月降息概率直接归零,甚至6月降息预期也会降温,届时美元走强、美债收益率上行,资金从高风险资产(BTC)流出,即利空币价,所以今晚如果有打算低多布局的还是要稍微谨慎一点。
目前通过盘面可以看到行情反弹至74,000后,出现小幅度回调,修复了MACD均线。经过昨日的下跌及震荡后,控头量能在逐渐递减。同时行情来到前期的二买点支撑附近获得支撑。白盘若进一步的在此震荡,那么晚间大概率会再次进行拉升。7万作为分水岭,没跌破之前短线依然属于多头。所以日内背靠七万回调做多即可。
目前通过盘面可以看到行情反弹至74,000后,出现小幅度回调,修复了MACD均线。经过昨日的下跌及震荡后,控头量能在逐渐递减。同时行情来到前期的二买点支撑附近获得支撑。白盘若进一步的在此震荡,那么晚间大概率会再次进行拉升。7万作为分水岭,没跌破之前短线依然属于多头。所以日内背靠七万回调做多即可。
BTC-2.46%

【当前用户分享了他的交易卡片,若想了解更多优质交易信息,请到 App 端查看】
- 赞赏
- 4
- 1
- 转发
- 分享
HighAmbition:
直达月球 🌕
距离2026年收官还剩:302天
0
- 赞赏
- 点赞
- 评论
- 转发
- 分享
这几年观察 AI 行业会越来越明显地感受到一个趋势,技术在进步但结构却在收紧。
模型越来越强,训练成本越来越高,算力门槛越来越大,最终形成的结果其实很清晰,AI 的进化路径逐渐集中在少数拥有资本、数据和算力资源的大型公司手中。
从某种意义上说这种集中化几乎是技术自然演化的结果,模型越强门槛越高参与者就越少。
但也正因为如此越来越多团队开始思考一个更根本的问题?AI 是否必须沿着这种集中化路径发展。
在这个问题上@0G_labs 的思路其实非常明确,他们并没有把目标局限在提升某一个模型的性能,而是试图改变 AI 生产的结构本身。
通过密码学验证机制与链上激励设计,让 AI 的训练、数据与算力贡献变成一个开放协作的网络。
在这样的体系里算力提供者、数据贡献者以及开发者都可以参与网络运行并通过可验证的方式获得对应激励。
其中一个很关键的设计是网络采用随机访问证明机制,节点可以证明自己真实持有数据或提供资源而不需要暴露具体的数据内容。
这个细节其实非常重要,长期以来大量高价值数据始终被封闭在私有数据库中。
医疗记录、法律文档、专业研究数据、代码库,这些数据对模型优化极其重要,但因为隐私与安全问题无法参与更广泛的训练协作。
当隐私计算与链上验证结合之后,这些数据第一次具备了在保护隐私前提下参与网络协作的可能。
与此同时网络的治理结构也在强化这种开放方向,网络升级、资源分配以及技术演进,可以通
模型越来越强,训练成本越来越高,算力门槛越来越大,最终形成的结果其实很清晰,AI 的进化路径逐渐集中在少数拥有资本、数据和算力资源的大型公司手中。
从某种意义上说这种集中化几乎是技术自然演化的结果,模型越强门槛越高参与者就越少。
但也正因为如此越来越多团队开始思考一个更根本的问题?AI 是否必须沿着这种集中化路径发展。
在这个问题上@0G_labs 的思路其实非常明确,他们并没有把目标局限在提升某一个模型的性能,而是试图改变 AI 生产的结构本身。
通过密码学验证机制与链上激励设计,让 AI 的训练、数据与算力贡献变成一个开放协作的网络。
在这样的体系里算力提供者、数据贡献者以及开发者都可以参与网络运行并通过可验证的方式获得对应激励。
其中一个很关键的设计是网络采用随机访问证明机制,节点可以证明自己真实持有数据或提供资源而不需要暴露具体的数据内容。
这个细节其实非常重要,长期以来大量高价值数据始终被封闭在私有数据库中。
医疗记录、法律文档、专业研究数据、代码库,这些数据对模型优化极其重要,但因为隐私与安全问题无法参与更广泛的训练协作。
当隐私计算与链上验证结合之后,这些数据第一次具备了在保护隐私前提下参与网络协作的可能。
与此同时网络的治理结构也在强化这种开放方向,网络升级、资源分配以及技术演进,可以通

- 赞赏
- 2
- 评论
- 转发
- 分享
加载更多
加入 4000万 人汇聚的头部社区
⚡️ 与 4000万 人一起参与加密货币热潮讨论
💬 与喜爱的头部博主互动
👍 查看感兴趣的内容
快讯
查看更多置顶
【千问公告】进场前请读完:我的交易室规则,不合规者请勿跟随 ⚡️
我是千问,Gate 年度收益榜 No.2(+2300%)。
为了维持长期稳定的复利曲线,从即日起,所有跟单者必须严格遵守以下三条硬性铁律:
1️⃣ 资金红线:严禁满仓跟单
禁止将全部身家押注在单一带单员身上。跟单资金请严格控制在个人总仓位的 30% 以内。 只有你能承受波动的压力,我才能带你抓到大级别的利润。
2️⃣ 止损铁律:单笔回撤 <5%
职业交易员不扛单。从即刻起,我将严格执行每单最大回撤不超过 5% 的风控方案。
我会用最小的代价去博取非对称收益。如果你追求的是永不损单的“幻象”,请绕道;如果你追求的是极致的风险收益比,请跟紧。
3️⃣ 信任周期:严禁频繁撤资
交易是概率的集合,不是每一分钟都在盈利。
案例背书: 1月至今,某跟单者从 100U 起步,期间历经多次震荡洗盘,因保持高度信任与耐心,截至今日(3月6日)已斩获 700U,实现 8倍 净利润。
如果你稍微看见一点浮亏就撤单,那你注定会错过随后的暴力翻倍。 ---
⚠️ 郑重警告:
我的交易室只欢迎理性、果断、有大格局的追随者。
如果你心态不稳、频繁上下车、无法忍受正常的战术回撤,请立即取消跟单,把名额留给真正懂交易的朋友。
看准趋势,尊重概率,共拿结果。
👇 执行入口:
#Gateio #千问 #职业风控 $ETH {currencycard:sGate 广场|3/5 今日话题: #比特币创下近一月新高
🎁 解读行情走势,抽 5 位锦鲤送出 $2,500 仓位体验券!
随着白宫表示已向参议院提交凯文·沃什担任美联储主席的提名,美国参议院未通过叫停特朗普打击伊朗的投票,比特币于今日凌晨创下 2 月 5 日以来新高,最高触及 74,050 美元,加密货币总市值回升突破 2.538 万亿美元。
💬 本期热议:
1️⃣ 凯文·沃什的提名是否意味着降息预期升温?
2️⃣ 当前关口,你是持币待涨、顺势追多,还是反手布局回调?
分享观点,瓜分好礼 👉️ https://www.gate.com/post
📅 3/6 15:00 - 3/8 12:00 (UTC+8)Gate 广场内容挖矿奖励继续升级!无论您是创作者还是用户,挖矿新人还是头部作者都能赢取好礼获得大奖。现在就进入广场探索吧!
创作者享受最高60%创作返佣
创作者奖励加码1500USDT:更多新人作者能瓜分奖池!
观众点击交易组件交易赢大礼!最高50GT等新春壕礼等你拿!
详情:https://www.gate.com/announcements/article/49802Gate 广场|3/4 今日话题: #美伊局势影响
🎁 化身广场“战地观察员”,抽 5 位锦鲤送出 $2,500 仓位体验券!
美伊冲突持续升级,霍尔木兹海峡陷入事实性封锁,伊拉克部分原油生产受影响。能源供应再度紧张,通胀预期抬头,股市与大宗商品市场波动加剧。
💬 本期热议:
1️⃣ 你关注到了哪些足以撼动市场的战争新进展?
2️⃣ 能源、航运、国防补给、避险资产(黄金/BTC)都受到了哪些影响?
3️⃣ 当前有哪些值得关注的多空机会?
分享观点,瓜分好礼 👉️ https://www.gate.com/post
布局 Gate TradFi 👉️ https://www.gate.com/tradfi
📅 3/4 15:00 - 3/6 12:00 (UTC+8)🚨 Gate 广场|紧急行情通报 #加密市场上涨
🎁 解读行情走势,抽 5 位锦鲤送出 $2,500 仓位体验券!
行情拉升!比特币涨至71113.6美元,过去24小时内涨6.0%;以太坊涨至2070.22美元,过去24小时内涨5.32%。山寨币集体回暖,市场情绪明显回升。
💬 本期热议:
1️⃣ 这波反弹是否正式开启行情?今晚如何布局?
2️⃣ 明日走势怎么看?结合消息面给出你的策略判断。
分享观点,瓜分好礼 👉️ https://www.gate.com/post
📅 3/5 18:00 - 3/6 18:00 (UTC+8)